As discussed in our previous post ‘Is Accuracy Sufficient for AI in 6G? (No, Calibration is Equally Important)’, reliable AI should be able to quantify its uncertainty, i.e., to “know when it knows” and “know when it does not know”. To obtain reliable, or well-calibrated, AI models, two types of approaches can be adopted: (i) training-based calibration, and (ii) post-hoc calibration. Training-based calibration modifies the training procedure by accounting for calibration performance, and includes methods such as Bayesian learning [1, 2], robust Bayesian learning [3, 4], and calibration-aware regularization [5]; while post-hoc calibration utilizes validation data to “recalibrate” a probabilistic model, as in temperature scaling [6], Platt scaling [7], and isotonic regression [8]. All these methods have no formal guarantees on calibration, either due to inevitable model misspecification [9], or due to overfitting to the validation set [10, 11]. In contrast, conformal prediction (CP) offers formal calibration guarantees, although calibration is defined in terms of set, rather than probabilistic, prediction [12].
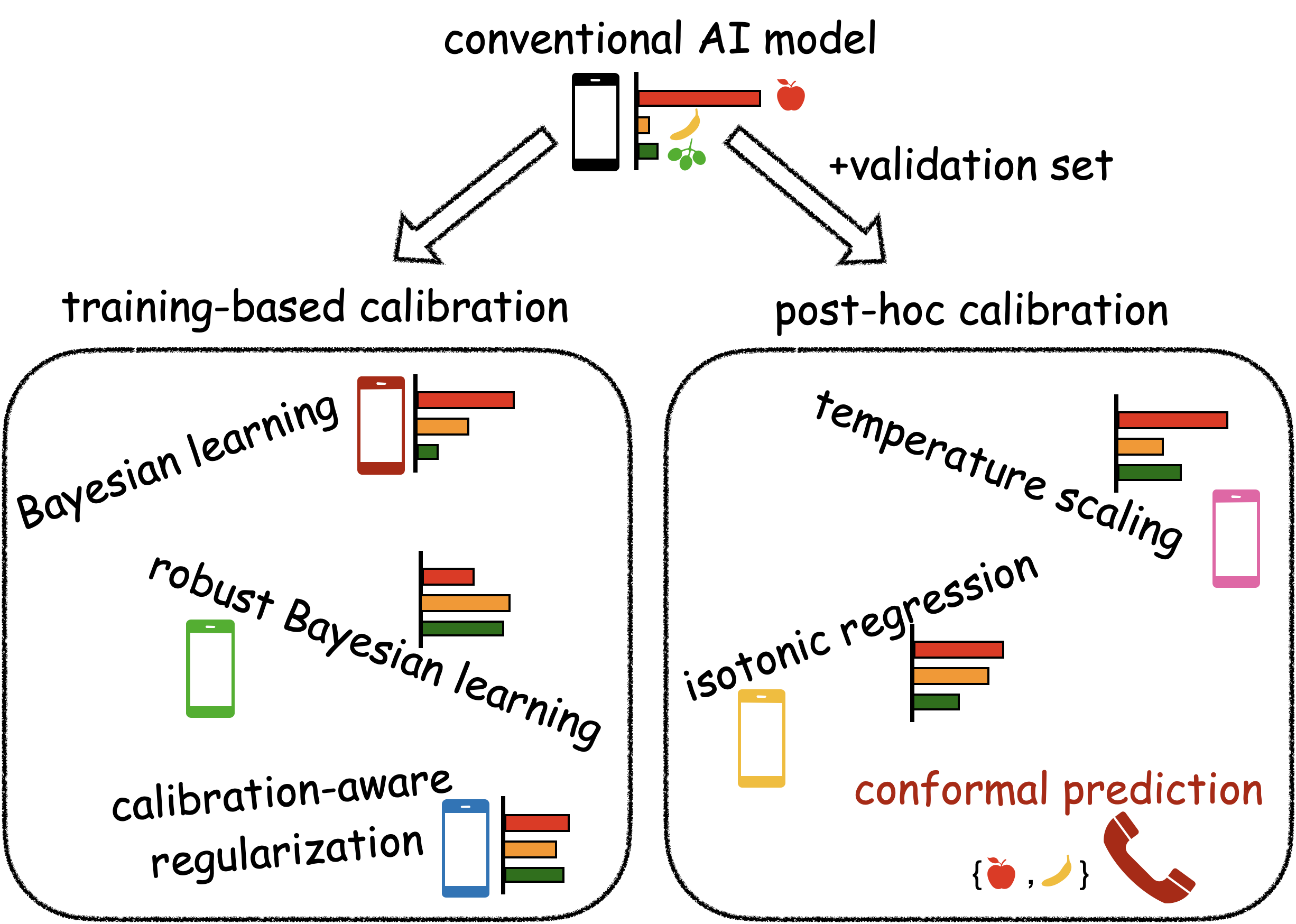
Fig. 1. Improvements in calibration can be obtained by either (i) training-based calibration or (ii) post-hoc calibration. Only conformal prediction, a post-hoc calibration approach, provides formal guarantees on calibration via set prediction.
A well-calibrated set predictor is the one that contains the true label with probability no smaller than a predetermined coverage level, say 90%. A set predictor obtained by conformal prediction is provably well calibrated, irrespective of the unknown underlying ground-truth distribution as long as the data examples are exchangeable, or i.i.d. (independent and identically distributed).
One could trivially build a well-calibrated set predictor by producing the entire label set as the predicted set. However, such set predictor would be completely uninformative, since the size of the set predictor determines how informative the set predictor is. While conformal prediction is always guaranteed to yield reliable set predictors, it may produce large predicted set size in the presence of limited data examples [13]. In our recent work, presented at the NeurIPS 2022 Workshop on Meta-Learning, we have introduced a novel method that enhances the informativeness of CP-based set predictors via meta-learning.

Fig. 2. Meta-learning transfers knowledge from multiple tasks. In our recent paper, we have proposed an application of meta-learning to conformal prediction with the aim of reducing the average prediction set size while preserving formal calibration guarantees.
Meta-learning, or learning to learn, transfers knowledge from multiple tasks to optimize the inductive bias (e.g., the model class) for new, related, tasks [14]. In our recent work, meta-learning was applied to cross-validation-based conformal prediction (XB-CP) [13] to achieve well-calibrated and informative set predictors. As demonstrated in the following figure, the proposed meta-learning approach for XB-CP, termed meta-XB, can reduce the average prediction set size as compared to conventional CP approaches (XB-CP and validation-based conformal prediction (VB-CP) [12]) and to previous work on meta-learning for VB-CP [14], while preserving the formal guarantees on reliability (the predetermined coverage level, 90%, is always satisfied for meta-XB).
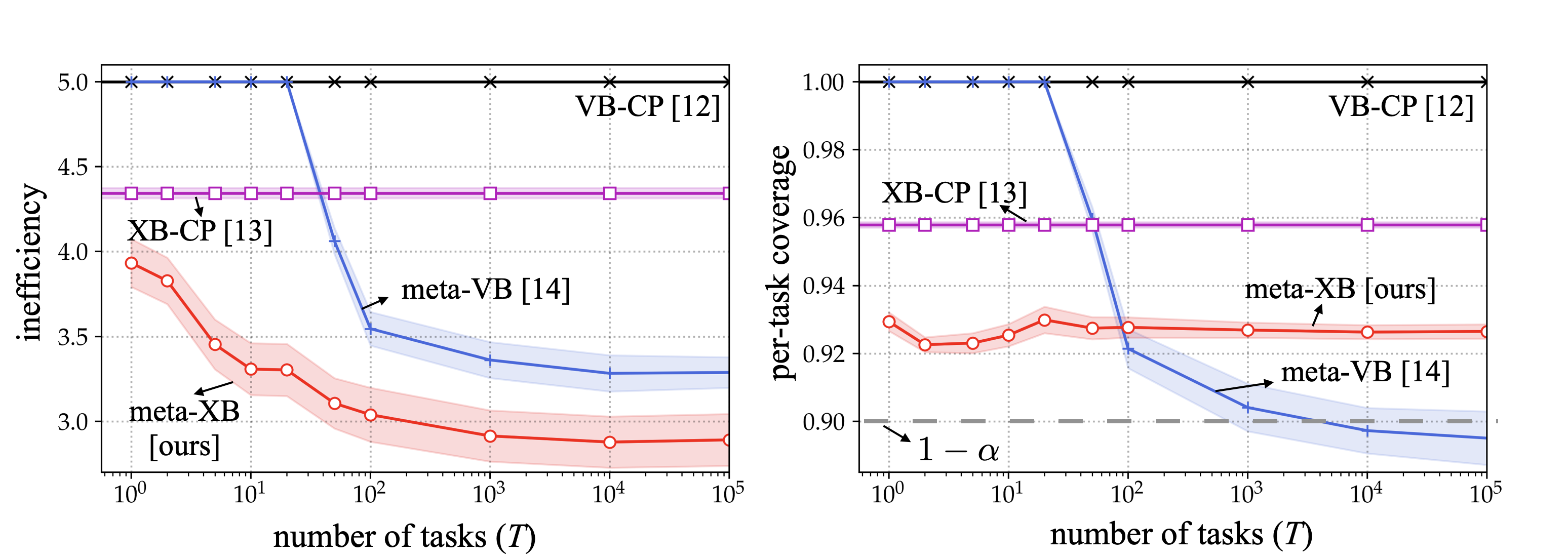
Fig. 3. Average prediction set size (left) and coverage (right) for new tasks as a function of number of meta-training tasks. As compared to conventional CP schemes (VB-CP and XB-CP), meta-learning based approaches (meta-VB and meta-XB) have smaller prediction set size; while the proposed meta-XB guarantees reliability for every task unlike meta-VB that satisfies coverage condition on average over multiple tasks.
For more details including improvements in terms of input-conditional coverage via meta-learning with adaptive nonconformity scores [15], and further experimental results on image classification and communication engineering aspects, please refer to the arXiv posting.
References
[1] O. Simeone, Machine learning for engineers. Cambridge University Press, 2022
[2] J. Knoblauch, et al, “Generalized variational inference: Three arguments for deriving new posteriors,” arXiv:1904.02063, 2019
[3] W. Morningstar, et al “PACm-Bayes: Narrowing the empirical risk gap in the Misspecified Bayesian Regime,” NeurIPS 2021
[4] M. Zecchin, et al, “Robust PACm: Training ensemble models under model misspecification and outliers,” arXiv:2203.01859, 2022
[5] A. Kumar, et al, “Trainable calibration measures for neural networks from kernel mean embeddings,” ICML 2018
[6] C. Guo, et al, “On calibration of modern neural networks,” ICML 2017
[7] J. Platt, et al, “Probabilistic outputs for support vector machines and comparisons to regularized likelihood method,” Advances in Large Margin Classifiers 1999
[8] B. Zadrozny and C. Elkan “Transforming classifier scores into accurate multiclass probability estimates,” KDD 2022
[9] A. Masegosa, “Learning under model misspecification: Applications to variational and ensemble methods.” NeurIPS 2020
[10] A. Kumar, et al, “Verified Uncertainty Calibration,” NeurIPS 2019
[11] X. Ma and M. B. Blaschko, “Meta-Cal: Well-controlled Post-hoc Calibration by Ranking,” ICML 2021
[12] V. Vovk, et al, “Algorithmic Learning in a Random World,” Springer 2005
[13] R. F. Barber, et al, “Predictive inference with the jackknife+,” The Annals of Statistics, 2021
[14] Chen, Lisha, et al. “Learning with limited samples—Meta-learning and applications to communication systems.” arXiv preprint arXiv:2210.02515, 2022.
[14] A. Fisch, et al, “Few-shot conformal prediction with auxiliary tasks,” ICML 2021
[15] Y. Romano, et al, “Classification with valid and adaptive coverage,” NeurIPS 2020
Leave a Reply