AI modules are being considered as native components of future wireless communication systems that can be fine-tuned to meet the requirements of specific deployments [1]. While conventional training solutions target the accuracy as the only design criterion, the pursuit of “perfect accuracy” is generally neither a feasible nor a desirable goal. In Alan Turing’s words, “if a machine is expected to be infallible, it cannot also be intelligent”. Rather than seeking an optimized accuracy level, a well-designed AI should be able to quantify its uncertainty: It should “know when it knows”, offering high confidence for decisions that are likely to be correct, and it should “know when it does not know”, providing a low confidence level for decisions are that are unlikely to be correct. An AI module that can provide reliable measures of uncertainty is said to be well-calibrated.
Importantly, accuracy and calibration are two distinct criteria. As an example, Fig. 1 illustrates a QPSK demodulator trained using limited number of pilots. Depending on the input, the trained probabilistic model may result in either accurate or inaccurate demodulation decisions, whose uncertainty is either correctly or incorrectly characterized.
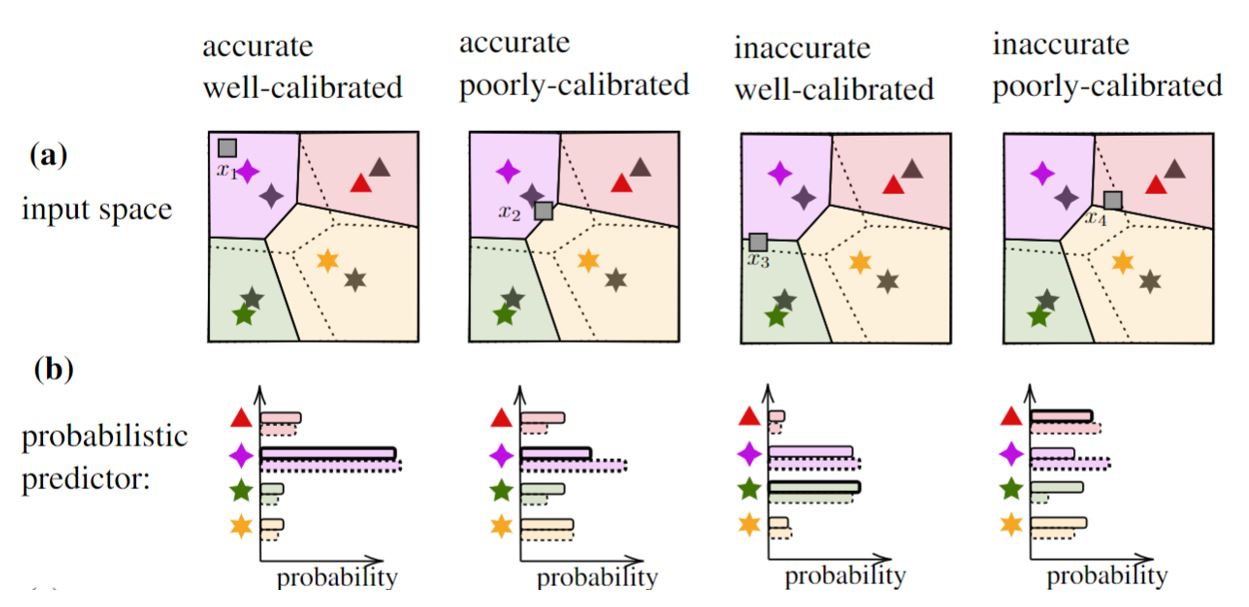
Fig. 1. The hard decision regions of an optimal demodulator (dashed lines) and of a data-driven demodulator trained on few pilots (solid lines) are displayed in panel (a), while the corresponding probabilistic predictions for some outputs are shown in panel (b).
The property of “knowing what the AI knows/ does not know” is very useful when the AI module is used as part of a larger engineering system. In fact, well-calibrated decisions should be treated differently depending on their confidence level. Furthermore, well-calibrated models enable monitoring – by tracking the confidence of the decisions made by an AI – and other functionalities, such as anomaly detection [2].
In a recent paper from our group published on the IEEE Transaction on Signal Processing [3], we proposed a methodology to develop well-calibrated and efficient AI modules that are capable of fast adaptation. The methodology builds on Bayesian meta-learning.
To start, we summarize the main techniques under consideration.
- Conventional, frequentist, learning ignores epistemic uncertainty – uncertainty caused by limited data – and tends to be overconfident in the presence of limited training samples.
- Bayesian learning captures epistemic uncertainty by optimizing a distribution in the model parameter space, rather than finding a single deterministic value as in frequentist learning. By obtaining decisions via ensembling, Bayesian predictors can account for the “opinions” of multiple models, hence providing more reliable decisions. Note that this approach is routinely used to quantify uncertainty in established fields like weather prediction [4].
- Frequentist meta-learning [5], also known as learning to learn, optimizes a shared training strategy across multiple tasks, so that it can easily adapt to new tasks. This is done by transferring knowledge from different learning tasks. As a communication system example, see Fig. 2 in which the demodulator adapts quickly with only few pilots for a new frame. While frequentist meta-learning is well-suited for adaptation purpose, its decisions tend to be overconfident, hence not improving monitoring in general.
- Bayesian meta-learning [6,7] integrates meta-learning with Bayesian learning in order to facilitate adaptation to new tasks for Bayesian learning.
- Bayesian active meta-learning [8] Active meta-learning can reduce the number of meta-training tasks. By considering streaming-fashion of availability of meta-training tasks, e.g., sequential supply of new frames from which we can online meta-learn the AI modules, we were able to effectively reduce the time required for satisfiable meta-learning via active meta-learning.
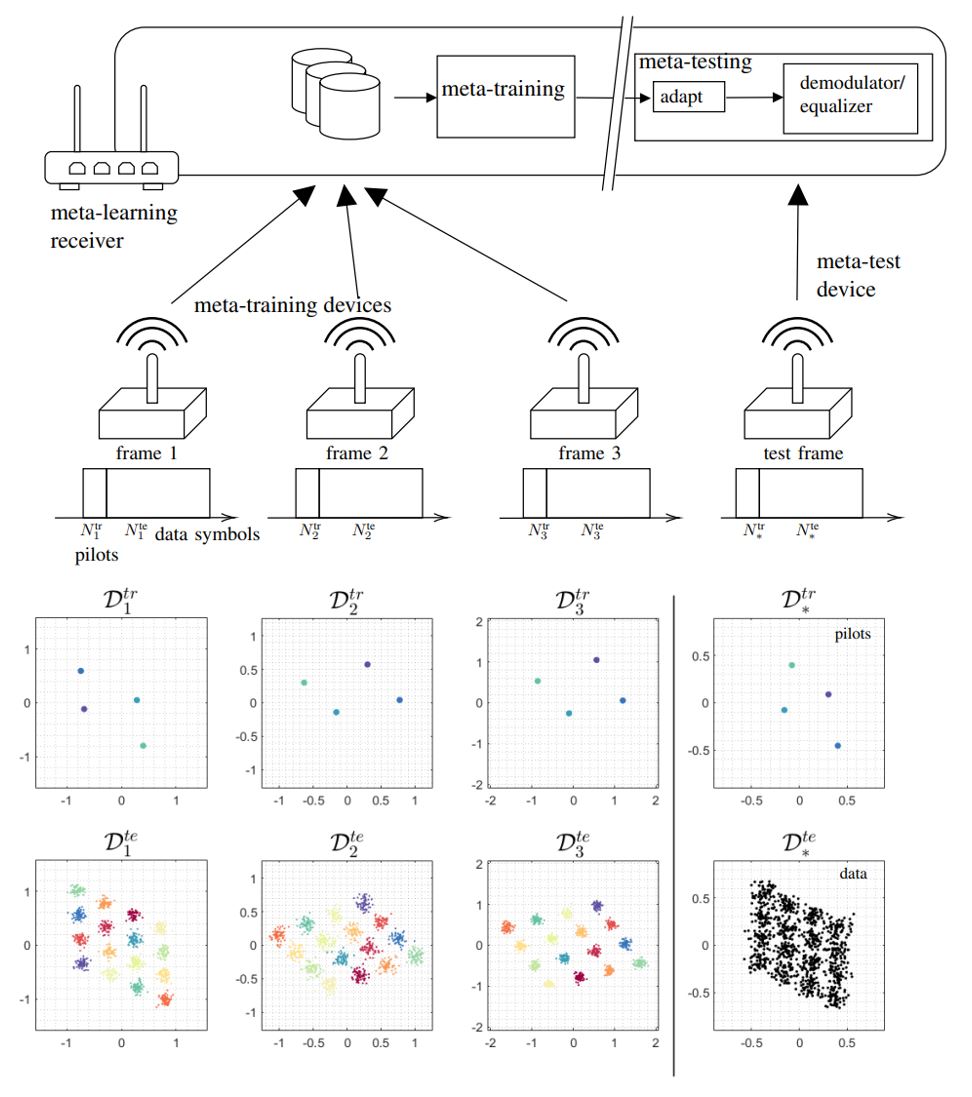
Fig. 2. Through meta-learning, a learner (e.g., demodulator) can be adapted quickly using few pilots to new environment, using hyperparameter vector optimized over related learning tasks (e.g., frames with different channel conditions).
Some Results
We first show the benefits of Bayesian meta-learning for monitoring purpose by examining the reliability of its decisions in terms of calibration. In Fig. 3, reliability diagrams for frequentist and Bayesian meta-learning are compared. For an ideal calibrated predictor, the accuracy level should match the self-reported confidence (dashed line in the plots). In can be easily checked that AI modules designed by Bayesian meta-learning (right part) are more reliable than the ones with Frequentist meta-learning (left part), validating the suitability of Bayesian meta-learning for monitoring purpose. Experimental results are obtained by considering a demodulation problem.
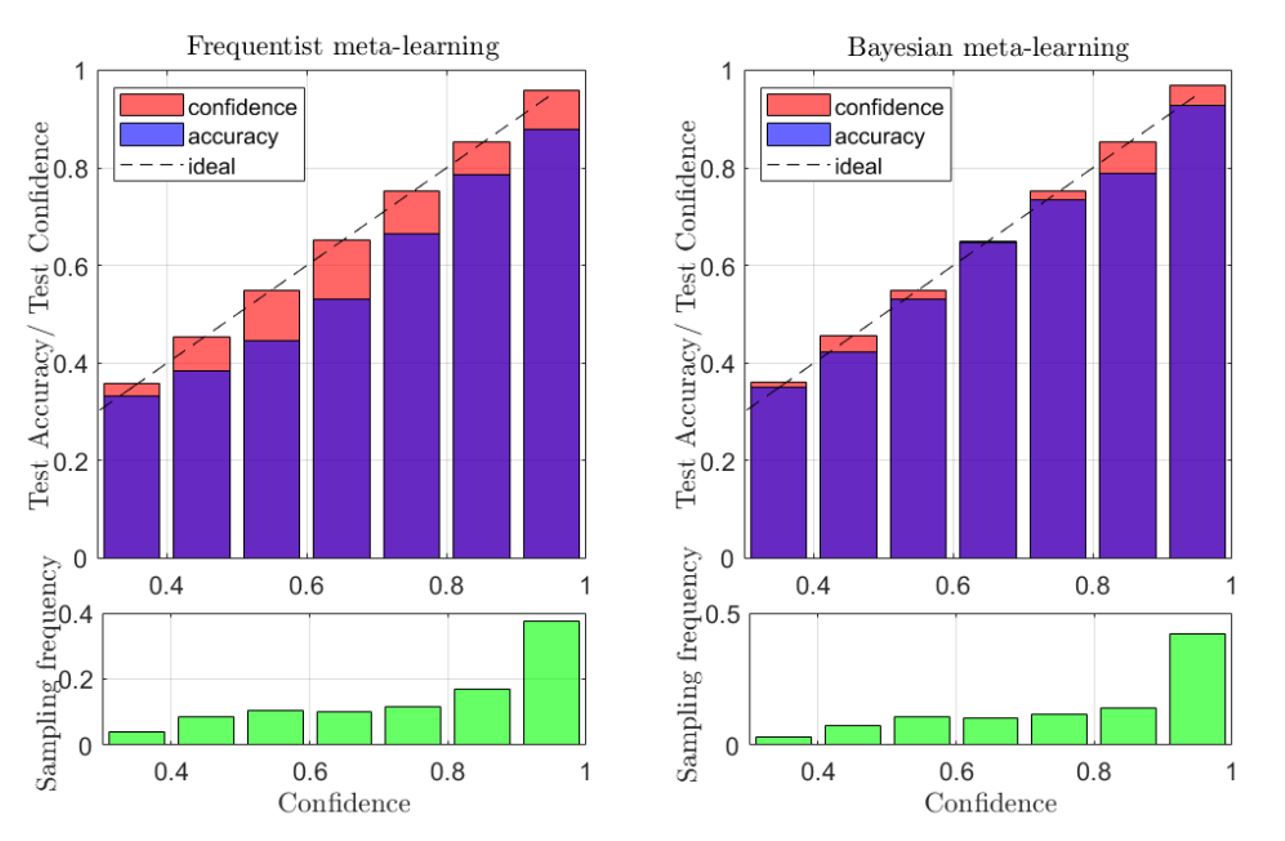
Fig. 3. Bayesian meta-learning (right) yields reliable decisions as compared to frequentist meta-learning (left) which can be captured via reliability diagrams [9].
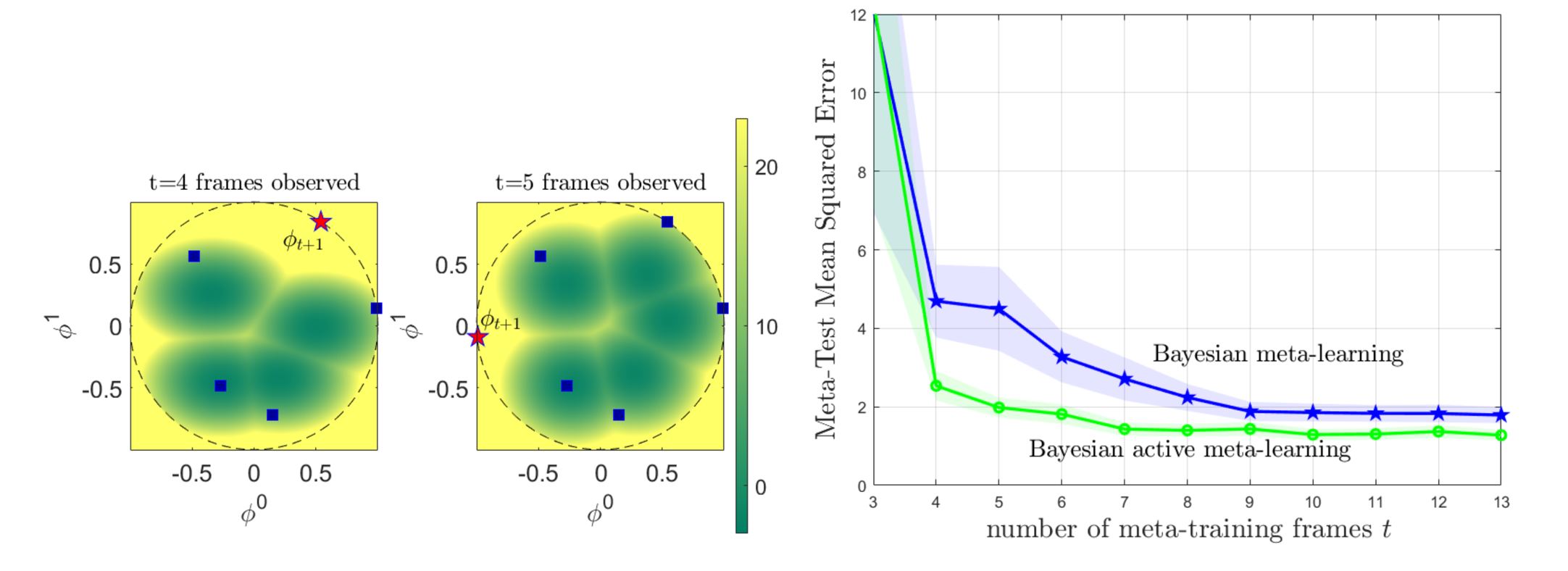
Fig. 4. Bayesian active meta-learning actively searches for meta-training tasks that are most surprising (left), hence increasing the task efficiency as compared to Bayesian meta-learning which randomly chooses tasks to be meta-trained.
References
[1] O-RAN Alliance, “O-RAN Working Group 2 AI/ML Workflow Description and Requirements,” ORAN-WG2. AIML. v01.02.02, vol. 1, 2.
[2] C. Ruah, O. Simeone, and B. Al-Hashimi, “Digital Twin-Based Multiple Access Optimization and Monitoring via Model-Driven Bayesian Learning,” arXiv preprint arXiv:2210.05582.
[3] K.M. Cohen, S. Park, O. Simeone and S. Shamai, “Learning to Learn to Demodulate with Uncertainty Quantification via Bayesian Meta-Learning,” arXiv https://arxiv.org/abs/2108.00785
[4] T. Palmer, “The Primacy of Doubt: From Climate Change to Quantum Physics, How the Science of Uncertainty Can Help Predict and Understand Our Chaotic World,” Oxford University Press, 2022.
[5] C. Finn, P. Abbeel, and S. Levine, “Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks,” in Proceedings of the 34th International Conference on Machine Learning, vol. 70. PMLR, 06–11 Aug 2017, pp. 1126–1135.
[6] J. Yoon, T. Kim, O. Dia, S. Kim, Y. Bengio, and S. Ahn, “Bayesian Model-Agnostic Meta-Learning,” Proc. Advances in neural information processing systems (NIPS), in Montreal, Canada, vol. 31, 2018.
[7] C. Nguyen, T.-T. Do, and G. Carneiro, “Uncertainty in Model-Agnostic Meta-Learning using Variational Inference,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2020, pp. 3090–3100.
[8] J. Kaddour, S. Sæmundsson et al., “Probabilistic Active Meta-Learning,” Proc. Advances in Neural Information Processing Systems (NIPS) as Virtual-only Conference, vol. 33, pp. 20 813–20 822, 2020.
[9] C. Guo, G. Pleiss, Y. Sun, and K. Q. Weinberger, “On Calibration of Modern Neural Networks,” in International Conference on Machine Learning. PMLR, 2017, pp. 1321–1330.
Leave a Reply