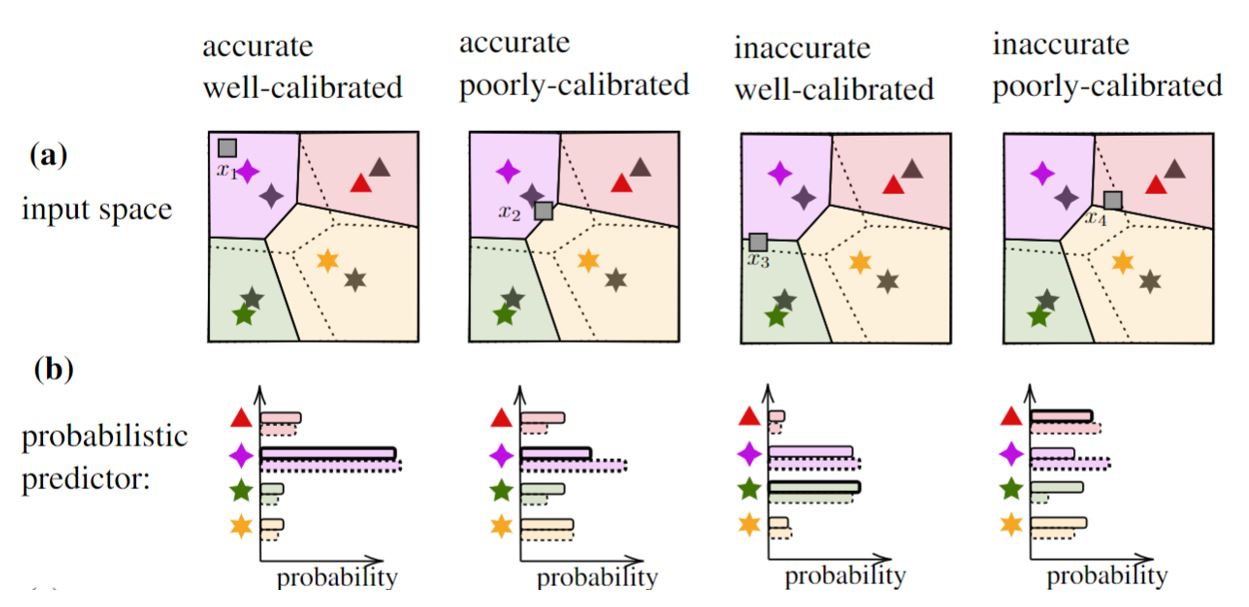
Motivation
Conformal risk control (CRC) [1] [2] is a recently proposed technique that applies post-hoc to a conventional point predictor to provide calibration guarantees. Generalizing conformal prediction (CP) [3], with CRC, calibration is ensured for a set predictor that is extracted from the point predictor to control a risk function such as the probability of miscoverage or the false negative rate. The original CRC requires the available data set to be split between training and validation data sets. This can be problematic when data availability is limited, resulting in inefficient set predictors. In [4], a novel CRC method is introduced that is based on cross-validation, rather than on validation as the original CRC. The proposed cross-validation CRC (CV-CRC) allows for the control of a broader range of risk functions, while proved to offer theoretical guarantees on the average risk of the set predictor, and reduced average set size with respect to CRC when the available data are limited.
Cross-Validation Conformal Risk Control
The objective of CRC is to design a set predictor with a mean risk no larger than a predefined level α, i.e.,
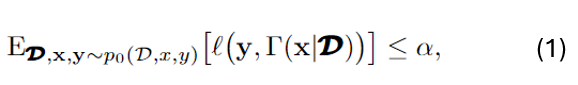
with test data input-label pair (x,y), and a set of N data pairs D.
The risk is defined between the true label y and a predictive set Γ of labels.
VB-CRC generalizes VB-CP [2] in the sense it allows the risk taking arbitrary form under technical conditions such as boundness and monotonicity in the set. VB-CP is resorted when VB-CRC considers the special case of the miscoverage risk
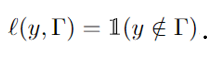
In this work, we introduce CV-CRC, which is a cross-validation-based version of VB-CRC. In a similar manner how CV-CP [5] generalizes VB-CP, CV-CRC generalizes VB-CRC. See Fig. 1 for illustration.
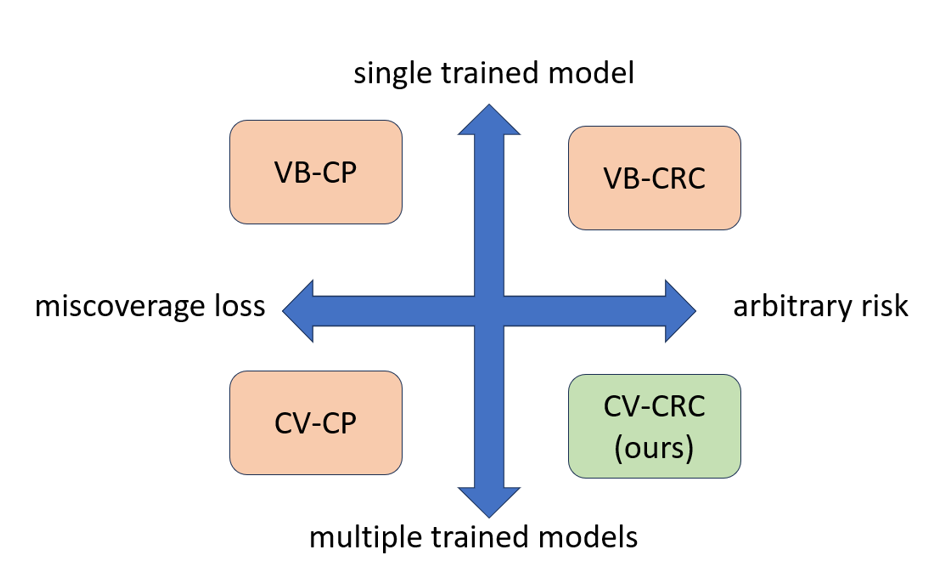
Fig. 1. (top) validation-based CRC (bottom) the proposed method, CV-CRC.
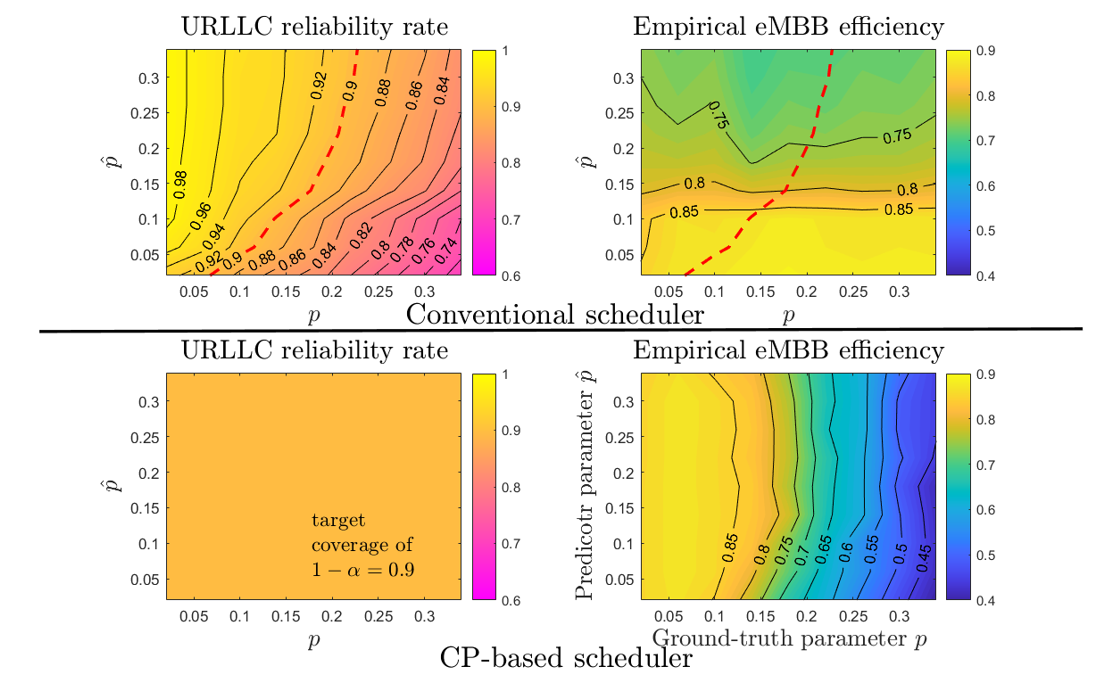
In the top panel of Fig. 2, VB-CRC is shown as the outcome of available data split into training data and validation data. The former is used to train a model, while the latter is used to post process and control a threshold λ. Upon test input x, a predictive set Γ of labels y’s is formed. In the bottom panel, CV-CRC is illustrated as a generalization. Available data is split K≤N folds, and K leave-fold-out models are trained. Then, K predictive sets are formed and merged via a threshold that is set via the trained models and the left-fold-out data.
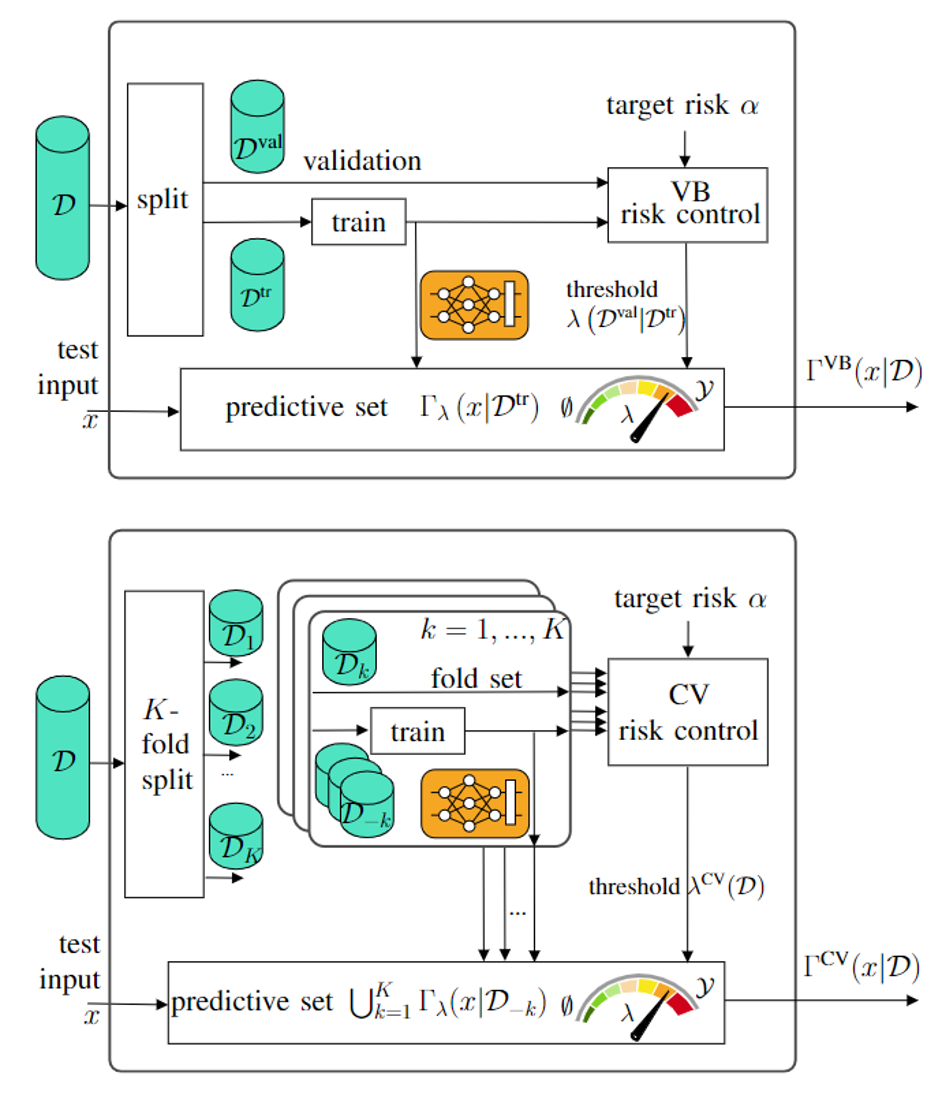
Fig. 2. (top) validation-based CRC (bottom) the proposed method, CV-CRC.
Experiments
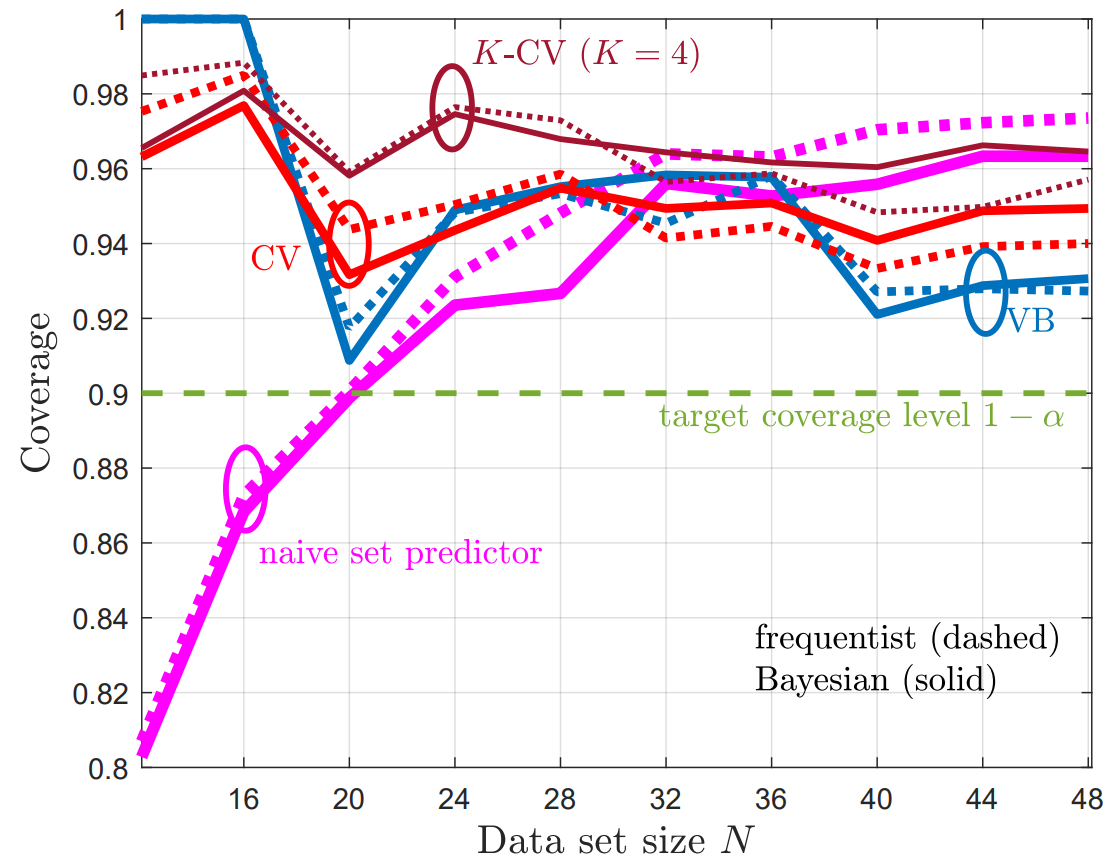
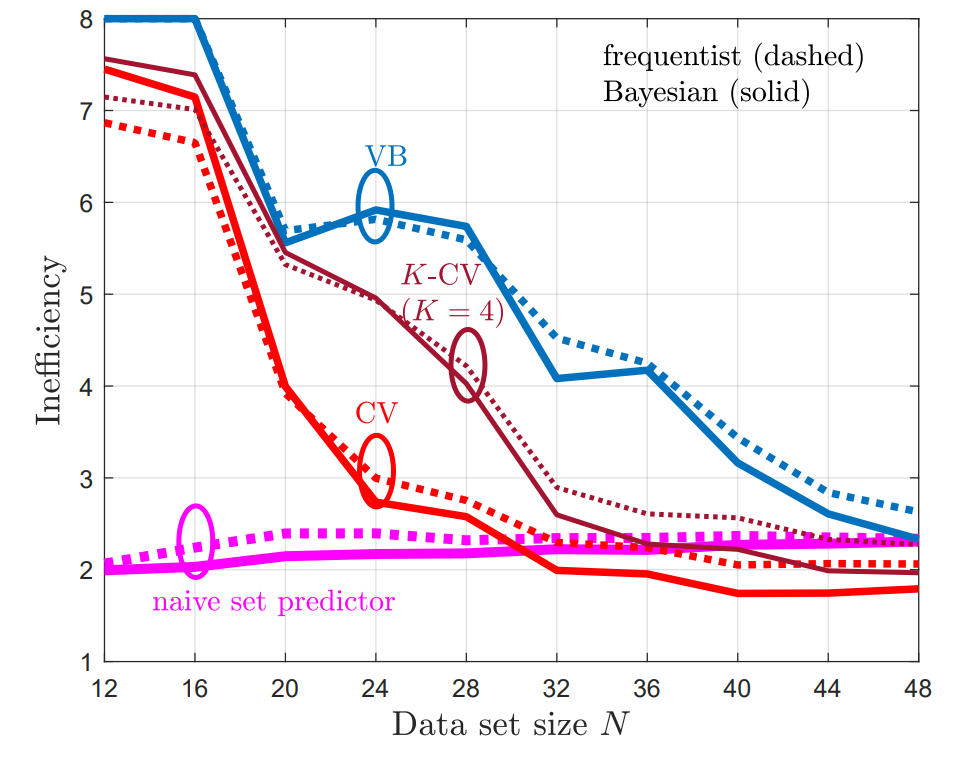
To illustrate the main theorem that the risk guarantee (1) is met, while the average set sizes are expected to reduce, two experiments were conducted. The first is vector regression using maximum-likelihood learning, and is shown in Fig. 3.
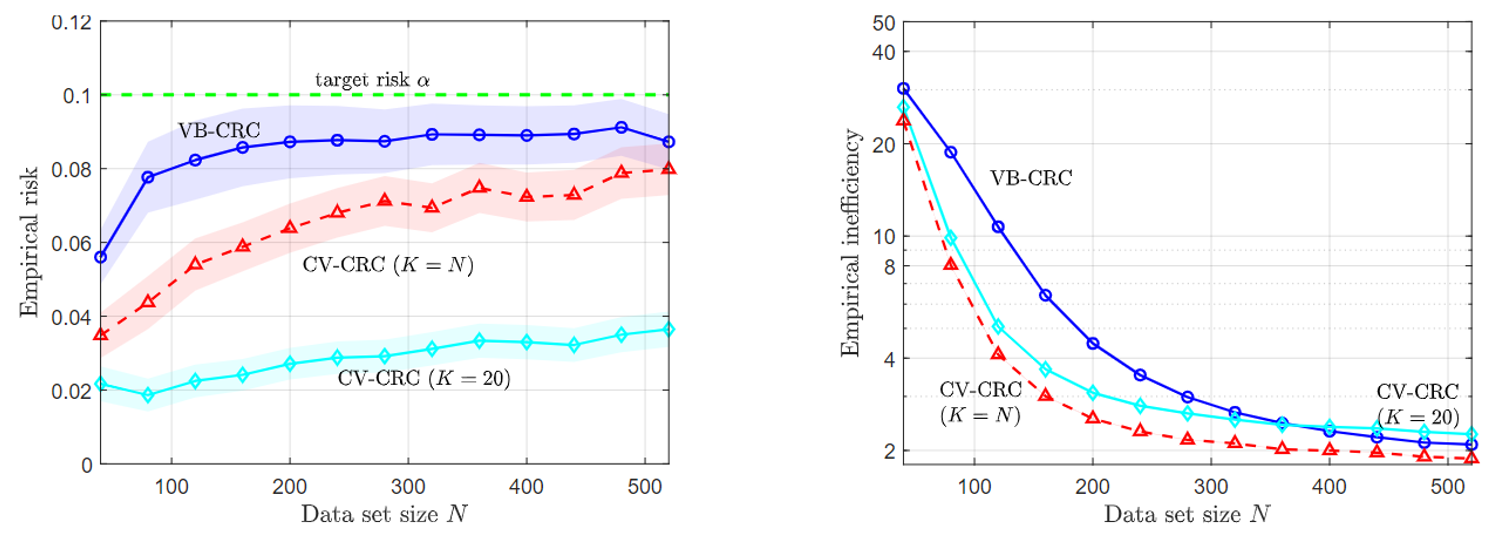
Fig. 3. VB-CRC and CV-CRC for the vector regression problem.
The second problem is a temporal point process prediction, where a point process set predictor aims to predict sets that contain future events of a temporal process with false negative rate of no more than a predefined α. As can be seen, in both problems, CV-CRC is shown to be more data-efficient in the small data regime, while holding the risk condition (1).
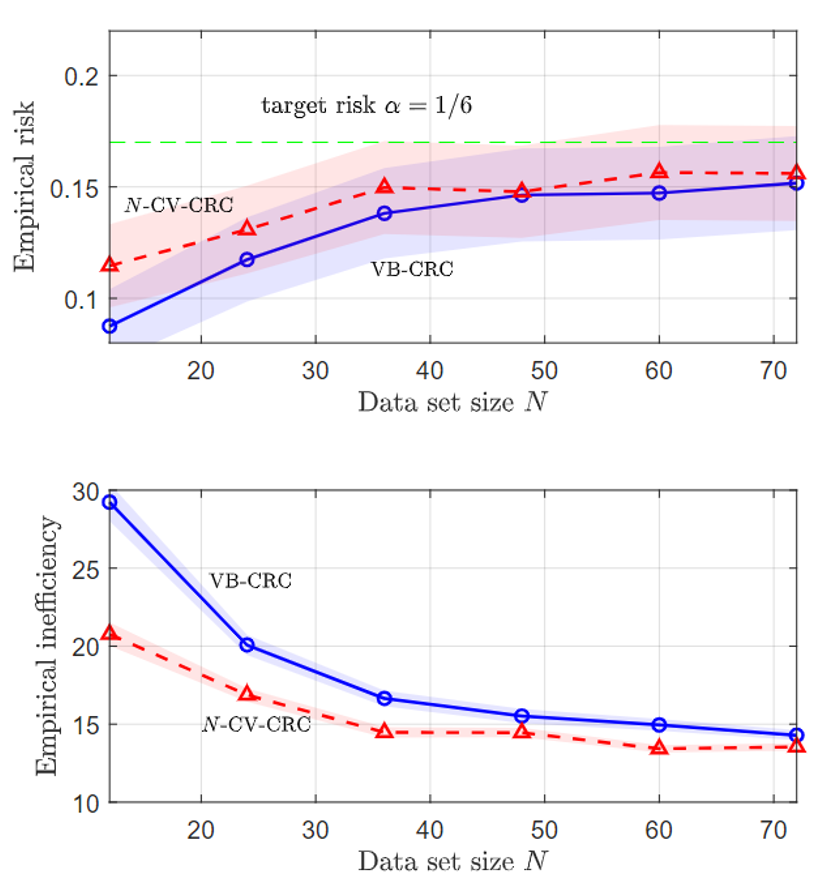
Fig. 4. VB-CRC and CV-CRC for the temporal point process prediction problem.
Full details can be found at ISIT preprint [4].
References
[1] A. N. Angelopoulos, S. Bates, A. Fisch, L. Lei, and T. Schuster, “Conformal Risk Control,” in The Twelfth International Conference on Learning Representations, 2024.
[2] S. Feldman, L. Ringel, S. Bates, and Y. Romano, “Achieving Risk Control in Online Learning Settings,” Transactions on Machine Learning Research, 2023.
[3] V. Vovk, A. Gammerman, and G. Shafer, Algorithmic Learning in a Random World. Springer, 2005, springer, New York.
[4] K. M. Cohen, S. Park, O. Simeone, and S. Shamai Shitz, “Cross-Validation Conformal Risk Control,” accepted to IEEE International Symposium on Information Theory Proceedings (ISIT2024), July 2024.
[5] R. F. Barber, E. J. Candes, A. Ramdas, and R. J. Tibshirani, “Predictive Inference with the Jackknife+,” The Annals of Statistics, vol. 49, no. 1, pp. 486–507, 2021.
Recent Comments