Motivation
Hyperparameter selection is a fundamental step in deploying machine learning models, aimed at assessing whether a model meets specified requirements in terms of performance, robustness, or safety. Recent approaches based on the Learn-Then-Test (LTT) [1] framework formulate this task as a multiple hypothesis testing procedure. For each candidate hyperparameter, LTT tests whether the corresponding model meets a target reliability level by evaluating it on multiple instances of the task (e.g., deploying the model in real-world scenarios). Despite its theoretical guarantees, LTT supports only non-adaptive testing, where all evaluation decisions and the length of the testing phase must be fixed in advance. This rigidity limits its practical utility in safety-critical environments, where minimizing the cost of testing is essential.
E-process-based testing
To overcome this limitation, our recent work—accepted at ICML 2025—introduces adaptive Learn-Then-Test (aLTT), a statistically rigorous, sequential testing framework that enables efficient, data-driven hyperparameter selection with provable reliability guarantees. The core innovation behind aLTT is its use of e-process-based multiple hypothesis testing [2], which replace the traditional p-value-based testing employed in LTT. E-processes support sequential, data-adaptive hypothesis testing while maintaining formal statistical guarantees.
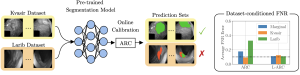
Practically speaking, as illustrated in Figure 1, this means that at each testing round, the experimenter can decide—based on the accumulated evidence—whether to continue testing specific hyperparameters or to stop if a sufficiently large set of reliable candidates has been identified. All of this is achieved without sacrificing the statistical guarantees of the procedure in terms of family-wise error rate (FWER) or false discovery rate (FDR) control. This stands in sharp contrast to p-value-based approaches, where such flexibility would invalidate the statistical guarantees of the procedure. An insidious problem known as p-hacking.

Figure 1: aLTT enables data-adaptive testing and flexible termination rules. At each testing round, based on the accumulated evidence, it is possible to decide which hyperparameters to test next and whether to continue testing.
Automated Prompt Engineering
The aLTT framework is broadly applicable to any setting where reliable configuration must be achieved under limited testing budgets. In our paper, we demonstrate its effectiveness in three concrete domains: configuring wireless network policies, selecting offline reinforcement learning strategies, and optimizing prompts for large language models. In the prompt engineering setting [3], the goal is to identify instructions (prompts) that consistently lead an LLM to generate accurate, relevant, or high-quality responses across tasks. Since each prompt must be tested by running the LLM—often a costly operation—efficiency is critical. aLTT enables the sequential testing of prompts, adaptively prioritizing those that show early promise and terminating the process once enough reliable prompts are found. As shown in Figure 2, this not only reduces the computational burden (yielding a higher true discovery rate under the same testing budget), but also leads to the discovery of shorter, more effective prompts—a valuable property in latency-sensitive or resource-constrained environments. The result: fewer evaluations, higher-quality prompts, and rigorous statistical reliability.

(Left) True positive rate as a function of the testing horizon attained by aLTT with $\epsilon$-greedy exploration and LTT. (Right) Length of the shortest prompt in the predicted set of reliable hyperparameters retuned by aLTT and LTT. aLTT needs fewer testing round to return high quality and short prompts
References
[1] Angelopoulos AN, Bates S, Candès EJ, Jordan MI, Lei L. Learn then test: Calibrating predictive algorithms to achieve risk control. arXiv preprint arXiv:2110.01052. 2021 Oct 3.
[2] Xu Z, Wang R, Ramdas A. A unified framework for bandit multiple testing. Advances in Neural Information Processing Systems. 2021 Dec 6;34:16833-45.
[3] Zhou Y, Muresanu AI, Han Z, Paster K, Pitis S, Chan H, Ba J. Large language models are human-level prompt engineers. InThe Eleventh International Conference on Learning Representations 2022 Nov 3.

Recent Comments