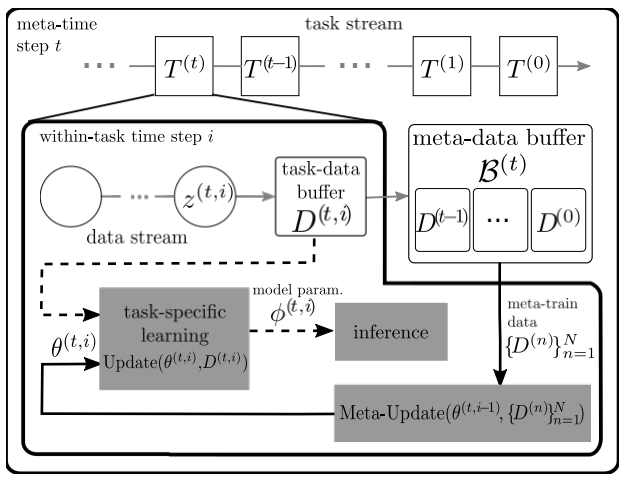
Problem
Machine learning models have become a ubiquitous tool for inference in various end-user applications such as natural language processing, face recognition and mobile healthcare management. In such highly personalized cases, it is important for the model to be able to adapt to the unique features of an individual with only a minimal amount of training data. Furthermore, the devices for which these personalized inference problems are relevant are typically power and/or memory constrained which limits the size of the model that can be used for learning on the edge.
Solution
In our recent work, accepted for publication in DSLW 2021, we focus on a solution using spiking neural networks (SNNs) that leverages the popular model agnostic meta-learning method to train a model that performs online inference while concurrently improving its ability to adapt to new tasks (termed online-within-online meta-learning (OWOML)-SNN). This meta-training method learns a hyperparameter initialization that can be quickly adapted to new tasks from a certain family as opposed to the standard paradigm in which a large ‘universal’ model is fixed at deployment. Biologically inspired SNN models that operate on sparse binary signals, are known to provide benefits in terms of energy efficiency, especially (as in our case) where a local learning rule would allow it to be implemented on a neuromorphic edge processor such as Intel’s Loihi chip.
As show in Fig. 1, the proposed system assumes a stream of tasks for the SNN to adapt to, with streaming within-task data that it can learn from for online inference. Data from past tasks is stored in a fixed size buffer to be used for the meta-learning update. When new data for the current task arrives, multiple SNNs are instantiated using the hyperparameter initialization. One of those SNNs is used for online learning and inference while the others implement the meta-learning update to the hyperparameter initialization for use in the next iteration.
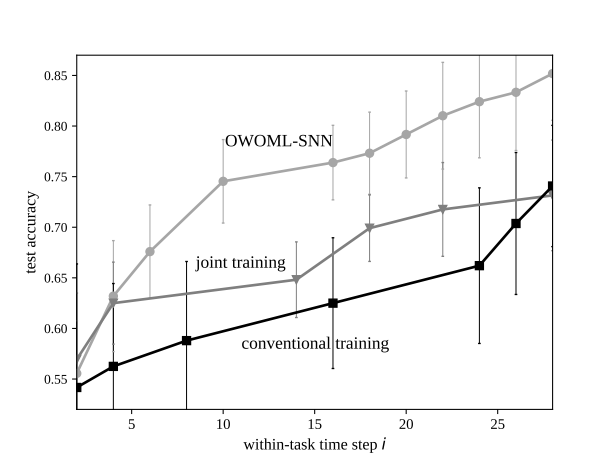
Results
The performance of OWOML-SNN is compared to conventional per-task training and joint training. Under conventional training, a single SNN model is randomly initialized and learns only from the data available for the current task to perform online inference. Under joint training the SNN learns a so called ‘universal’ initialization by standard training across all previous tasks and then does per-task adaptation. We consider the family of omniglot character 2-way classification tasks with rate encoding to test the within-task generalization capabilities of our meta-learner.
The results in Fig. 2 for test accuracy over training at convergence of the hyperparameter initialization and joint training initialization show that the meta-learned initialization enables the fastest online adaptation of the three, providing an improvement in accuracy over conventional training that is about 18% larger that that of joint training after training on 5 examples from each class.
Please see our paper for further details.
Bleema Rosenfeld
Leave a Reply