–when the SNR is small enough
Problem Description
Federated Learning (FL) refers to distributed protocols that avoid direct raw data exchange among the participating devices while training for a common learning task. This way, FL can potentially reduce the information on the local data sets that is leaked via communications. Nevertheless, the model updates shared by the devices may still reveal information about local data. For example, a malicious server could potentially infer the presence of an individual data sample from a learnt model by membership inference attack or model inversion attack.
Differential privacy (DP) quantifies information leaked about individual data points by measuring the sensitivity of the disclosed statistics to changes in the input data set at a single data point. DP can be guaranteed by introducing a level of uncertainty into the released model that is sufficient to mask the contribution of any individual data point. The most typical approach is to add random perturbations, e.g., Gaussian. This suggests that, when FL is implemented in wireless systems, the channel noise can directly act as a privacy-inducing mechanism.
Suggested Solution
In recent work, we have designed differentially private wireless distributed gradient descent via the direct, uncoded, transmission of gradients from devices to edge server. The channel noise is utilized as a privacy preserving mechanism and dynamic power control is separately optimized for orthogonal multiple access (OMA) and non-orthogonal multiple access (NOMA) protocols with the goal of minimizing the learning optimality gap under privacy and power constraints across a given number of communication blocks. Our recent work to appear in IEEE Journal on Selected Areas in Communications tackles this problem. One of our main results shows that, as long as the privacy constraint level, measured via DP, is below a threshold that decreases with the signal-to-noise ratio (SNR), uncoded transmission achieves privacy “for free”, i.e., without affecting the learning performance. As our analysis demonstrates, channel noise added in the first iterations tends to impact convergence less significantly than the noise added in later iterations, whereas the privacy level depends on a weighted sum of the inverse noise power across the iteration. These properties, captured by compact analytical expressions derived in this paper, are leveraged for adaptive power allocation, yielding significant performance gains over standard static power allocation.
Some Results
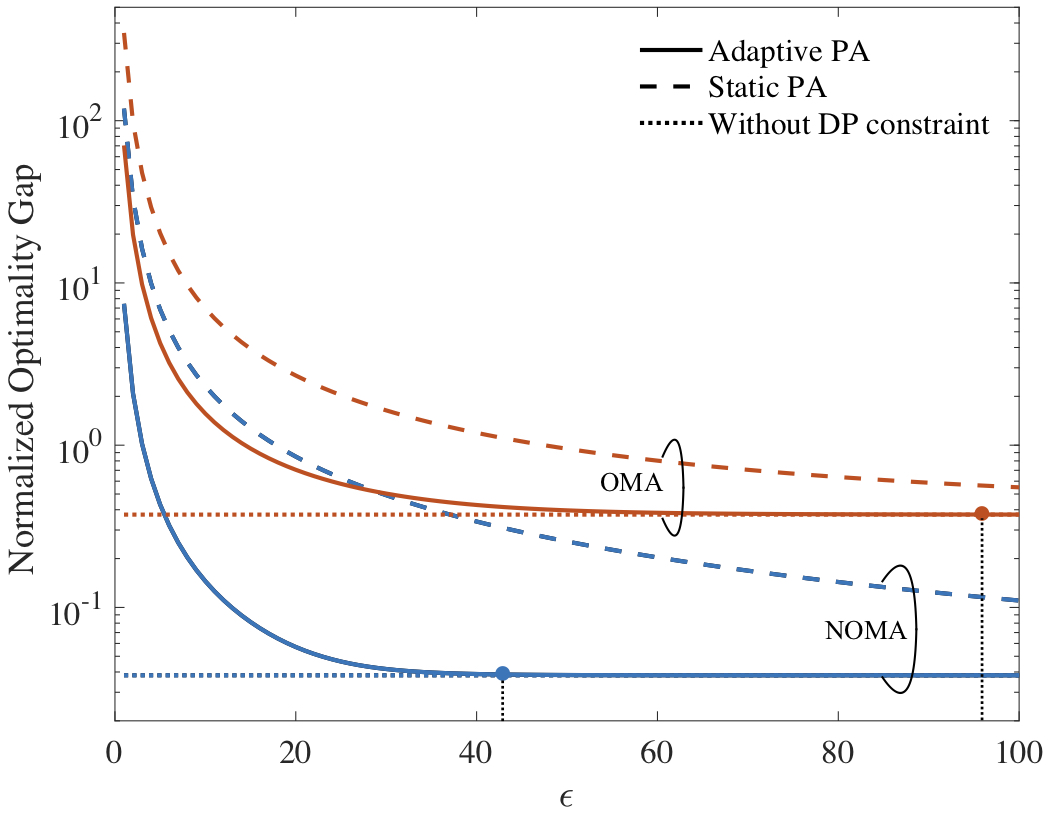
The performance is first evaluated by using randomly generated synthetic dataset. In the considered range of DP level, as illustrated in the figure below, NOMA with either adaptive or static power allocation (PA) achieves better performance than OMA. Furthermore, the proposed adaptive PA obtains a significant performance gain over static PA under stringent DP constraints, while the performance advantage of adaptive PA decreases as the DP constraint is relaxed. The figure also shows the threshold values of DP level beyond which the privacy “for free”.
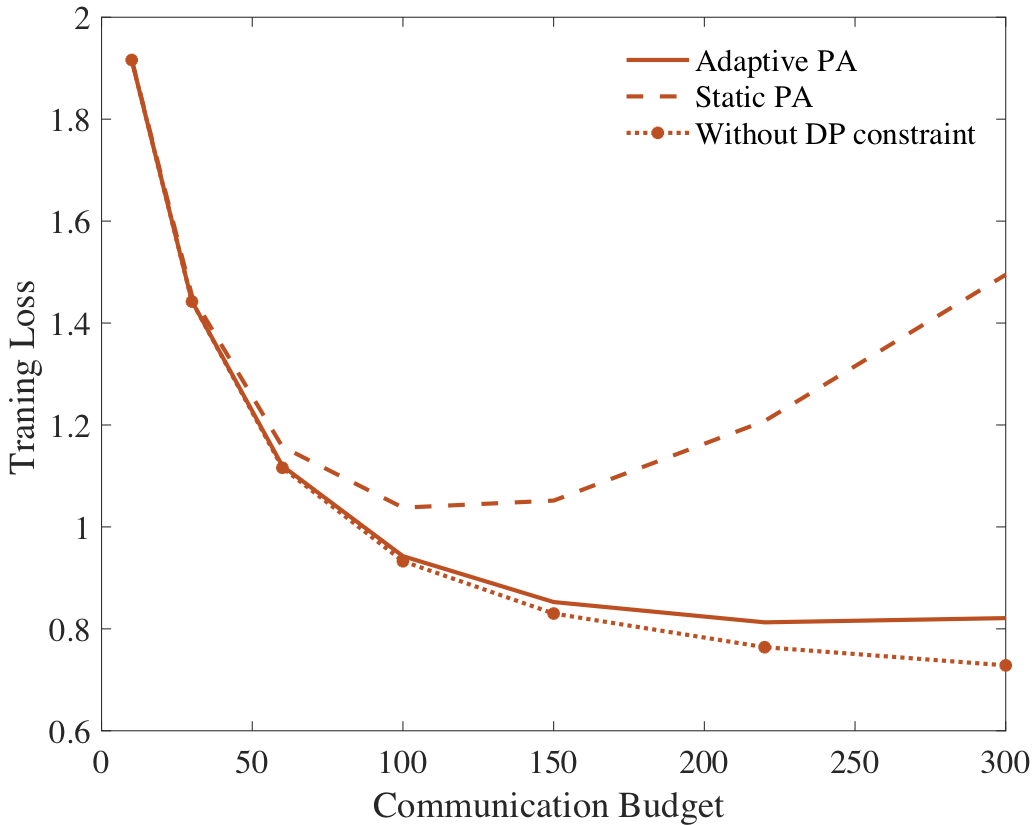
The performance is also evaluated by MNIST data set as summarized in the last figure. With conventional static PA, the increasing communication budget is seen to largely degrade performance. This is because more communication blocks may cause an increase in privacy loss. In contrast, adaptive PA is able to properly allocate power across the communication blocks thereby achieves a lower training loss.
Leave a Reply