Problem
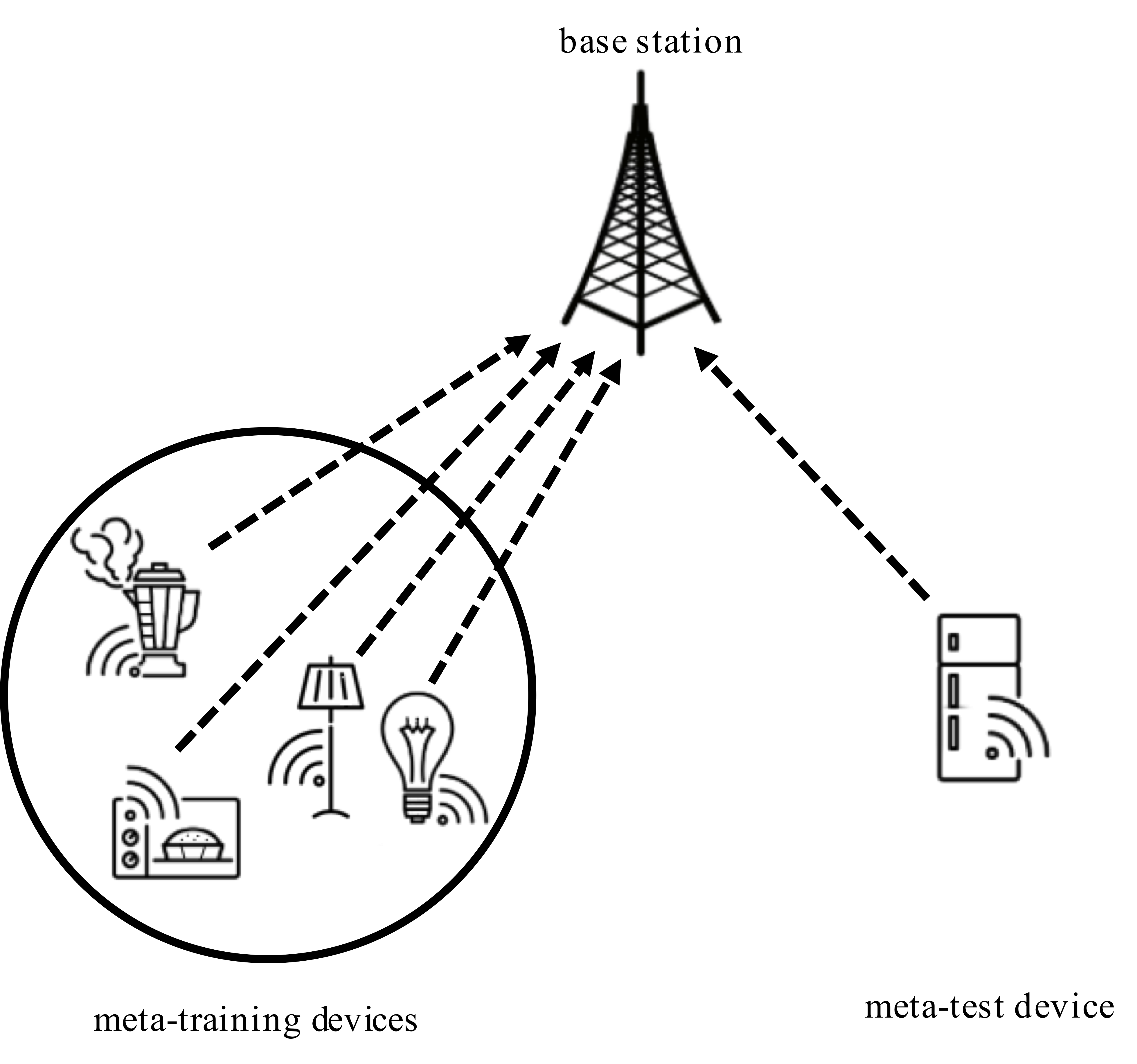
Fig. 1: Illustration of few-pilot training for an IoT system via meta-learning
For channels with an unknown model or an unavailable optimal receiver of manageable complexity, the design of demodulation and decoding can potentially benefit from a data-driven approach based on machine learning. Machine learning solutions, however, cannot be directly applied to Internet- of-Things (IoT) scenarios in which devices transmit sporadically using short packets with few pilot symbols. In fact, the few pilots do not provide enough data for training the receiver.
A Novel Solution based on Meta-learning
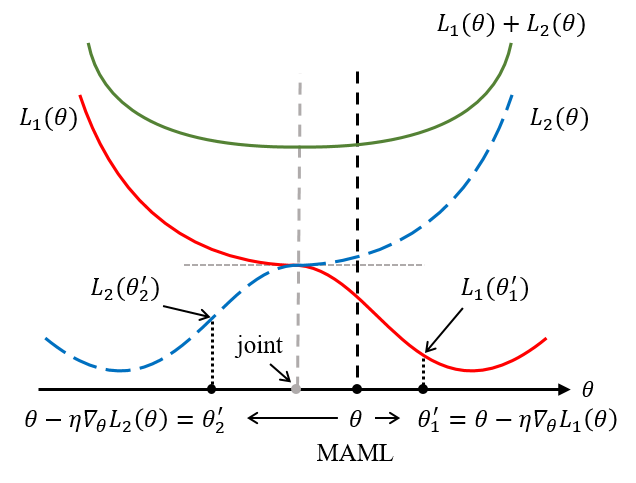
Fig. 2: MAML is to find an initial value 𝜃 that minimizes the loss L𝑘(θ´𝑘) for all devices 𝑘 after one step of update. In contrast, joint training carries out an optimization on the cumulative loss L1(θ) + L2(θ)
In a recent work to be presented at IEEE SPAWC 2019, we proposed a novel solution for demodulation in IoT networks that is based on model-agnostic meta-learning (MAML) algorithm. The key idea is to use pilots from previous transmissions of other IoT devices as meta- training data in order to learn a demodulator that is able to quickly adapt to the end-to-end channel conditions of a new device from few pilots. MAML derives an inductive bias as an initialization point for a neural network-based demodulator. As illustrated in Fig. 2, MAML seeks an initialization point such that all the performance losses of the demodulators for all IoT devices obtained after one update are collectively minimized. In comparison, a more conventional approach to use meta-training data, namely joint training, would pool together all the pilots received from the meta-training devices and seeks for minimizing the cumulative loss.
Some Results
To give a taste of the results in the paper, we now provide an example.
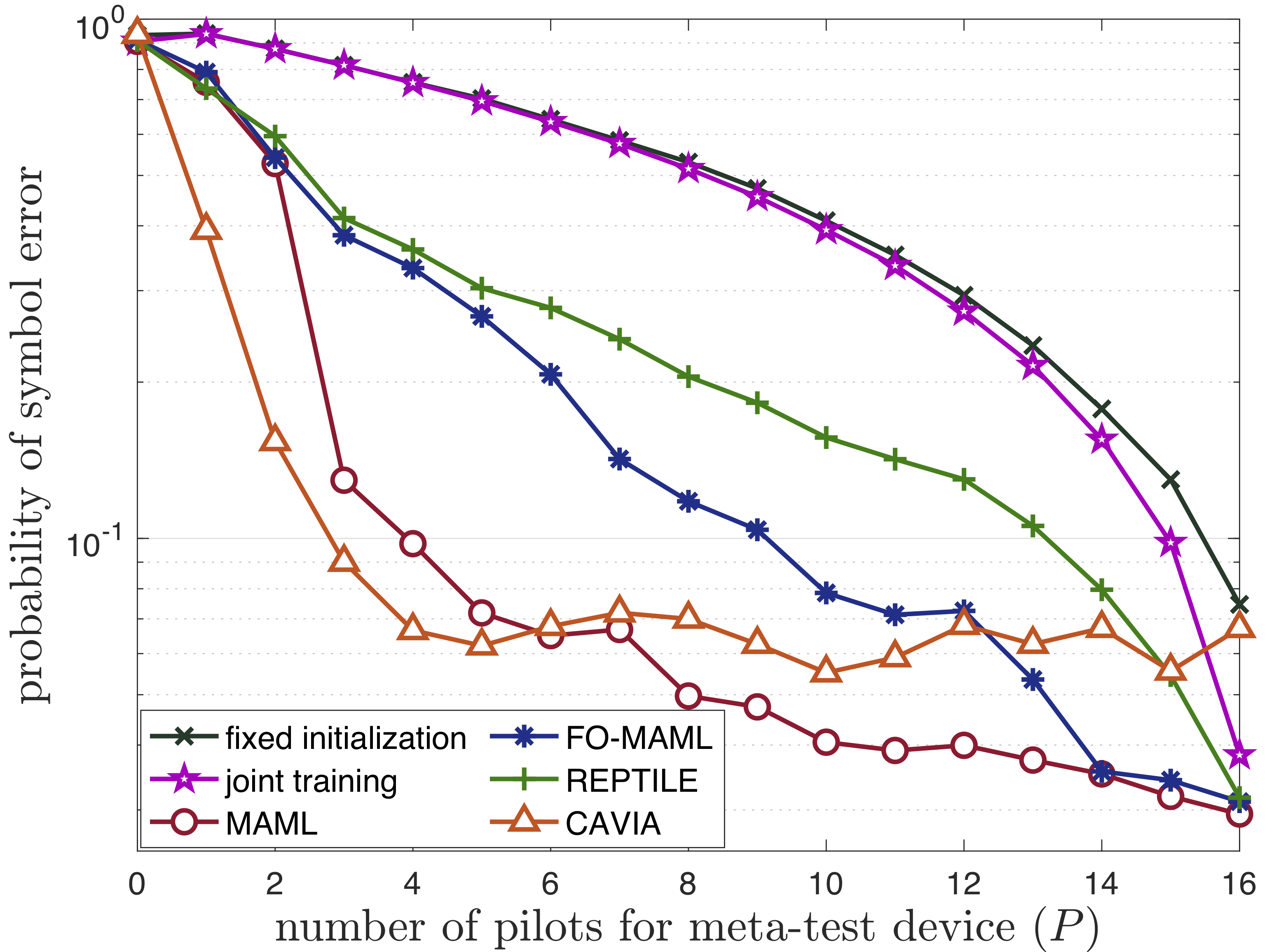
Fig. 3: Probability of symbol error with respect to number of pilots for the meta-test device (see paper).
In Fig. 3, we plot probability of symbol error with respect to the number of pilots for new IoT device in offline scenario. We adopt 16-QAM with 100 meta-training devices, each with 32 pilots for meta-training. We compare the performance of state-of-the-art meta-learning approaches including MAML with: (i) a fixed initialization scheme where data from the meta-training devices is not used; (ii) joint training with the meta-training dataset as described above.
All of the various meta-learning schemes are seen to vastly outperform the mentioned baseline approaches (i) – (ii) by adapting to the channel of the meta-test device using only a few pilots. In contrast, joint training shows similar performance compared to fixed initialization. This confirms that, unlike conventional solutions, meta-learning can effectively transfer information from meta-training devices to a new target device.
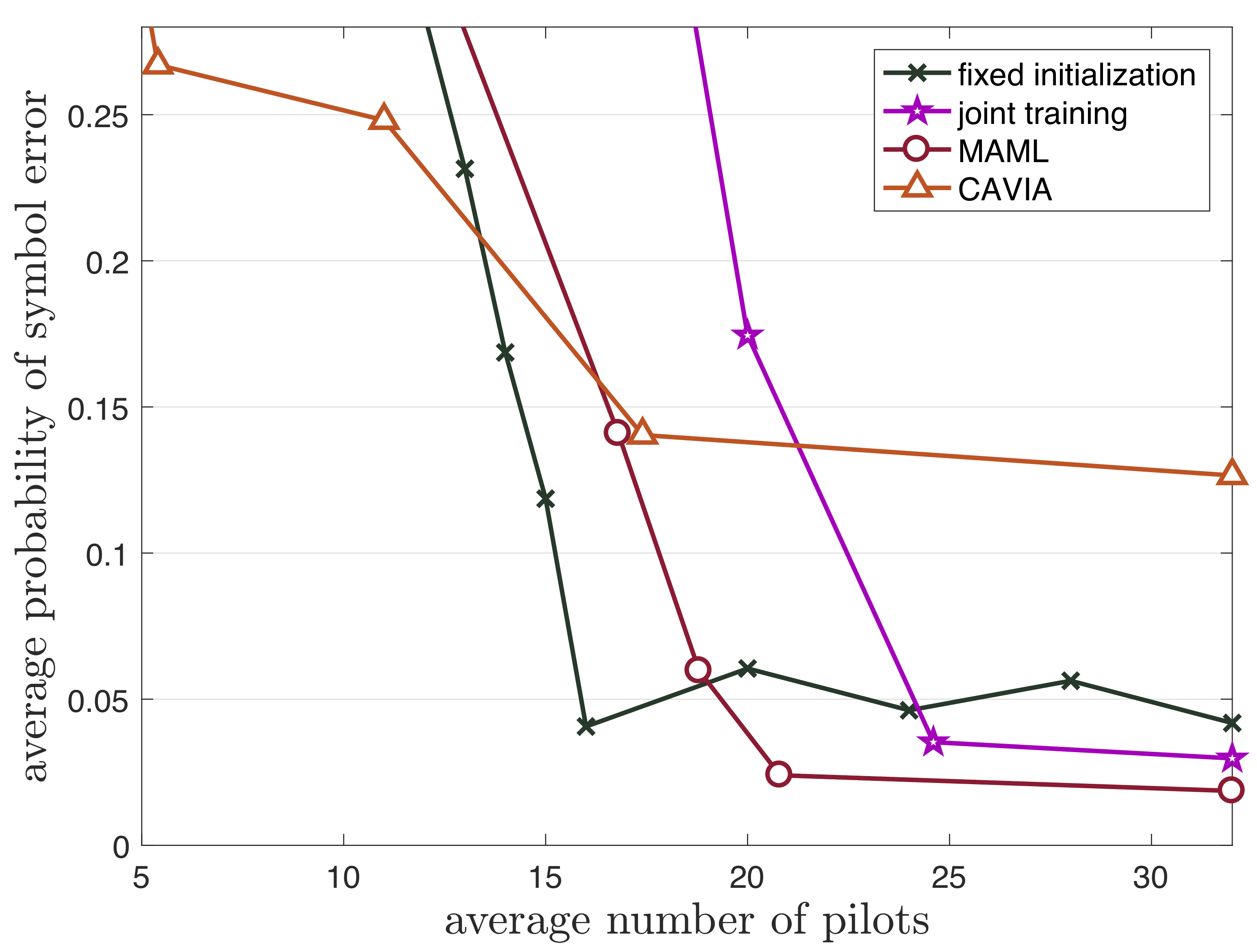
Fig. 4: Average probability of symbol error with respect to average number of pilots over slots t=71, …, 90 for online meta-learning (see paper).
In Fig. 4, we plot probability of symbol error with respect to average number of pilots in online scenario. Through comparison with fixed initialization case, we have shown that proposed adaptive pilot number selection scheme can reduce pilot overhead with any online schemes. Moreover, when proposed scheme comes with online meta-learning, we show that pilot overhead is reduced even more under negligible performance degradation. This again confirms that meta-learning can acquire useful inductive bias from previous IoT devices.
The full paper can be found here.
Recent Comments