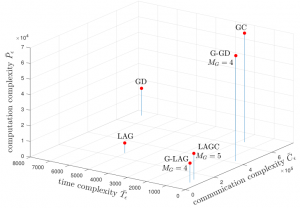
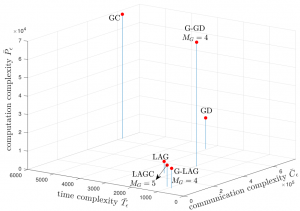
Problem
With the advent of 5G, cellular systems are expected to play an increasing role in enabling Internet of Things (IoT). This is partly due to the introduction of NarrowBand IoT (NB-IoT), a cellular-based radio technology allowing low-cost and long-battery life connections, in addition to other IoT protocols that operate in the unlicensed band such as LoRa. However, these protocols allow for a successful transmission only when a radio resource is used by a single IoT device. Therefore, generally, the amount of resources needed scales with the number of active devices. This poses a serious challenge in enabling massive connectivity in future cellular systems. In our recent IEEE Transactions on Wireless Communications paper, we tackle this issue.
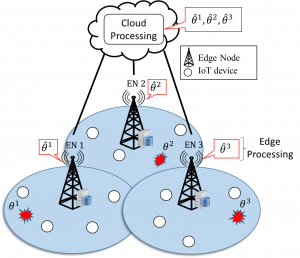
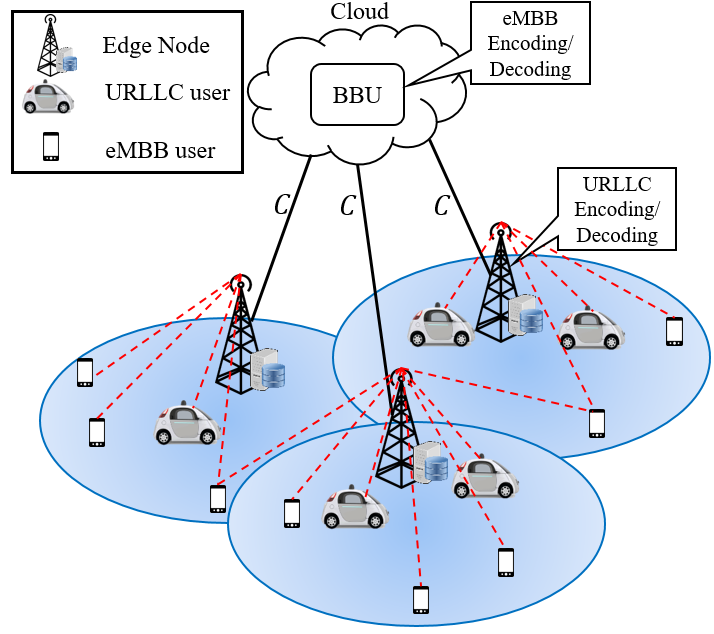
Figure 1: A Fog-Radio architecture where processing information from IoT devices, denoted by the theta symbol, can take place either at the Cloud or the Edge Node.
Suggested Solution
In our new paper, we propose an information-centric radio access technique where IoT devices making (roughly) the same observation of a given monitored quantity, e.g., temperature, transmit using the same radio resource, i.e., in a non-orthogonal fashion. Thus, the number of radio resources needed scales with the number of possible relevant values observed, e.g., high or low temperature and not with the number of devices.
Cellular networks are evolving toward Fog-Radio architectures, as shown in Figure 1. In these systems, instead of the entire processing happening at the edge node, radio access related functionalities can be distributed between the cloud and the edge. We propose that detection in the IoT system under study be implemented at either cloud or edge depending on backhaul conditions and on the statistics of the observations.
Some Results
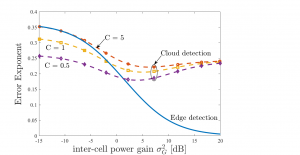
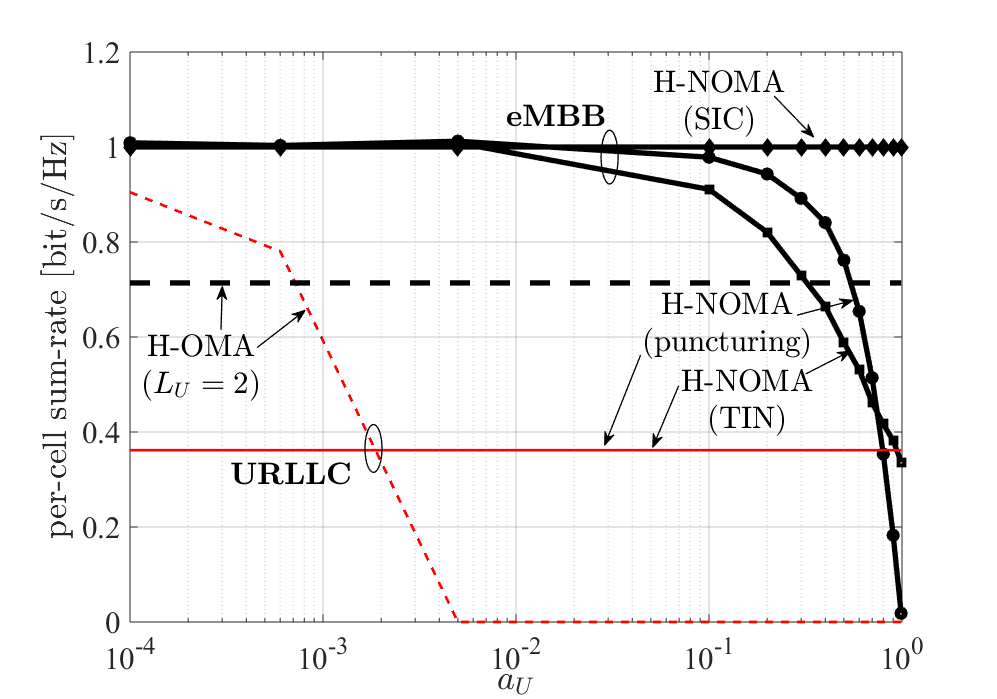
One of the important findings of this work is that cloud detection is able to leverage inter-cell interference in order to improve detection performance, as shown in the figure below. This is mainly due to the fact that devices transmitting the same values in different cells are non-orthogonally superposed and thus, the cloud can detect these values with higher confidence.
More details and results can be found in the complete version of the paper here.
Recent Comments