Motivation
Servicing ultra-reliable and low-latency communication (URLLC) traffic typically calls for a pre-emptive allocation of resources in order to meet stringent delay constraints. A conservative static allocation of resources for URLLC may guarantee desired levels of reliability and latency, but this comes at the expense of other services, most notably enhanced mobile broadband (eMBB), which cannot use the resources reserved for URLLC. A dynamic allocation of resources, while potentially more efficient, is made challenging by the stochastic nature of URLLC data packet generation. A promising solution is the adoption of predictors of URLLC data packet generation. Concretely, with reference to Fig. 1, a base station can deploy a predictor of URLLC data packet generation for the following frame, so as to guide the adaptive allocation of slots for URLLC packets, leaving the other slots available for eMBB users.
Background
URLLC traffic
A URLLC traffic must hold two restrictions:
- Ultra-Reliability – a portion of at least 1-α of all generated packets must be scheduled for transmission.
- Low-Latency – Each packet should have a unique schedule resource, no later than a predefined acceptable latency.
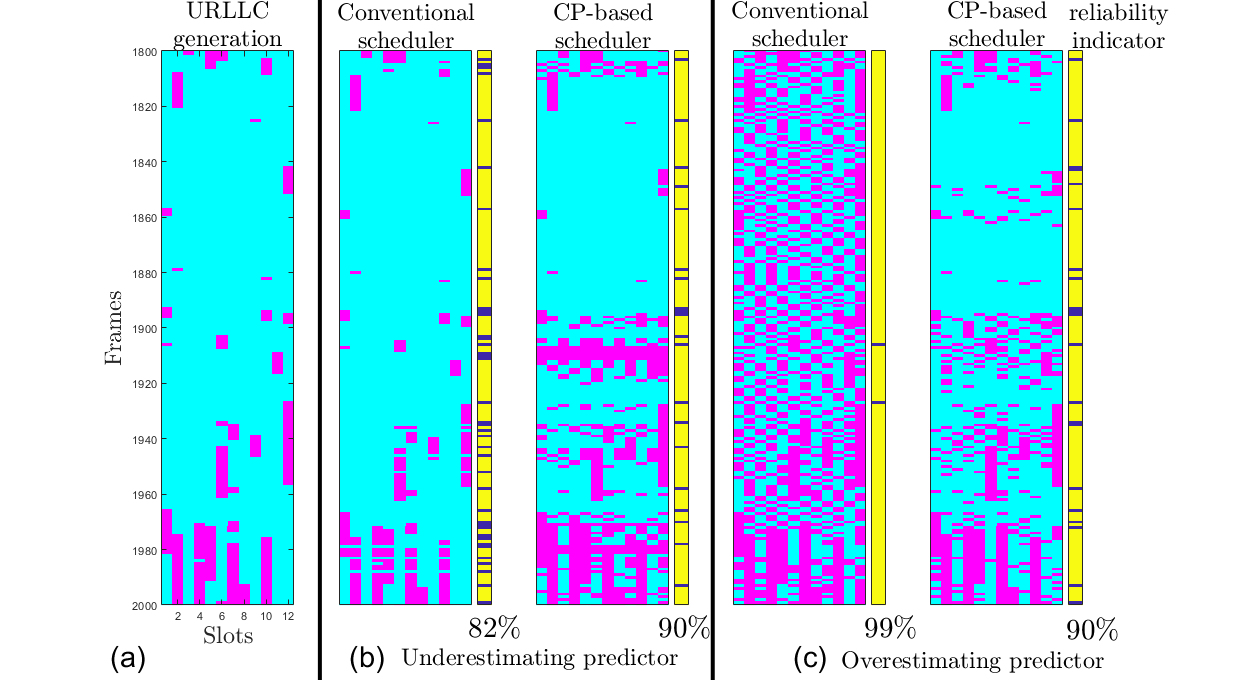
Fig 1 (a) URLLC traffic ground true generation patterns; (b) using a predictor that underestimates the traffic dynamics leads to unreliable URLLC allocation. CP-based is able to compensate successfully; (c) using a predictor that overestimates the traffic dynamics leads to overreliable URLLC allocation, i.e., low eMBB efficiency. CP-based is able to compensate successfully this as well.
Online Conformal Prediction
CP is a class of post-hoc calibration methods that transform standard probabilistic model into a set predictor that is guaranteed to contain the true target with probability no smaller than a predetermined coverage level [1]. Online CP alleviates the limitation of conventional CP of requiring a separate calibration data at the cost of providing time-averaged, rather than ensemble, reliability guarantees [2,3]. The adoption of CP in communication engineering was proposed in [Cohen2023ICASSP], which focused on wireless applications such as symbol demodulation, modulation classification, and received signal strength prediction.
Guaranteed Dynamic Scheduling
In our new work [4], accepted at IEEE Signal Processing Letters, we introduce a novel scheduler for URLLC packets that provides formal guarantees on reliability and latency irrespective of the quality of the URLLC traffic predictor.
Fig. 2(a) illustrates the frame-based segmentation. Fig. 2(b) shows 4 URLLC generated packets and 6 pre-emptively allocated URLLC resources, yet the latest packet is not allocated a resource within the allowed latency. In contrast, Fig. 2(c) show an allocation that meets the constraints, even though the number of URLLC resources are smaller. This leaves a better portion for eMBB traffic.
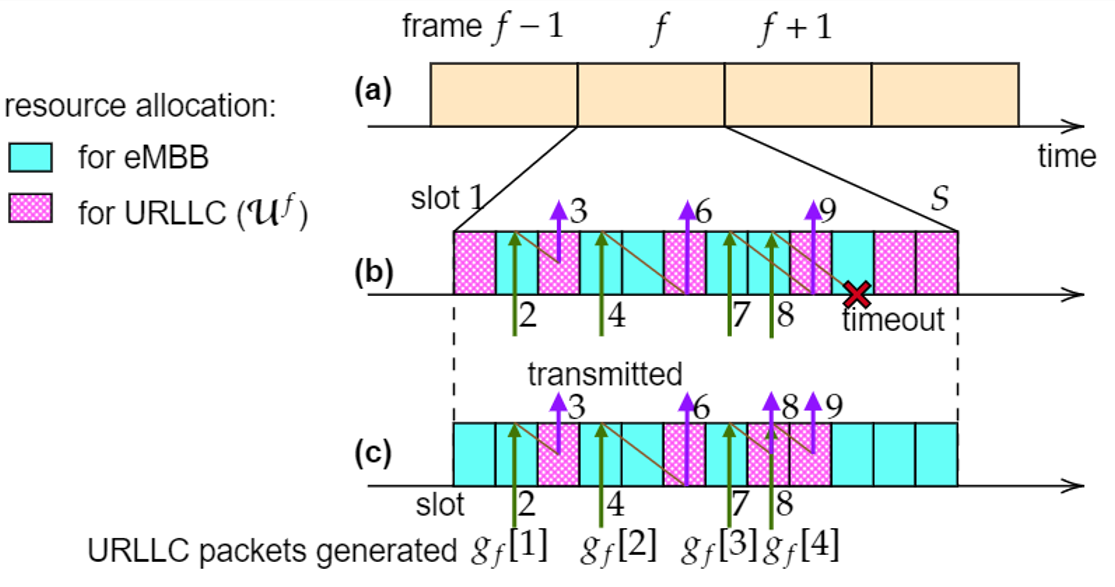
Fig. 2 (a) Frame-based timelinel; (b) miscovered allocation; (c) well-covered allocation.
The proposed method leverages recent advances in online CP, and follows the principle of dynamically adjusting the amount of allocated resources so as to meet reliability and latency requirements set by the designer. To this end, we adjust a threshold that changes between frames on the basis of a reliability condition, that controls how conservative the predictor of the next frame is.
Experiments
We consider two mismatched predictors: the first underestimates the dynamic of changes the URLLC traffic, while the second overestimates.
Fig. 3 investigates of the impact of such mismatches between URLLC model parameter and ground-truth model parameter. For some parameters values of mismatch, the conventional scheduler does not hold reliability to the desired level, while for the other it may result in over reliability. The conventional scheduler is significantly affected by a mismatch between predictor and ground-truth packet generation mechanism, yielding either ill empirical coverage (below 1-α) or over coverage. In contrast, the CP-based predictor is able to flatten the coverage to asymptotically reach the long-term target 1-α.
.
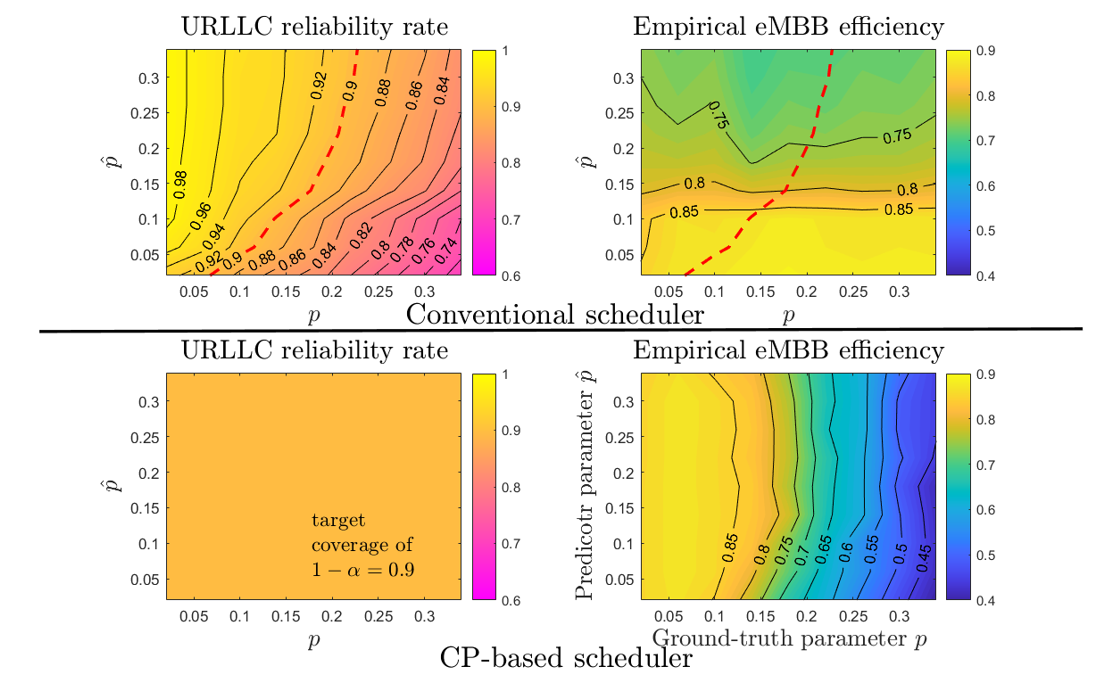
Fig. 3 Empirical URLLC reliability rate and eMBB efficiency. CP-based scheduler flattens out the coverage
Full details can be found at this SPL preprint [4].
[1] Vovk, Vladimir, Alexander Gammerman, and Glenn Shafer. “Algorithmic learning in a random world,” Vol. 29. New York: Springer, 2005.
[2] Gibbs, Isaac, and Emmanuel Candes. “Adaptive conformal inference under distribution shift.” Advances in Neural Information Processing Systems 34 (2021): 1660-1672.
[3] Feldman, Shai, Stephen Bates, and Yaniv Romano. “Conformalized Online Learning: Online Calibration Without a Holdout Set.” arXiv preprint arXiv:2205.09095 (2022).
[4] Cohen, Kfir M., Sangwoo Park, Osvaldo Simeone, Petar Popovski, and Shlomo Shamai. “Guaranteed Dynamic Scheduling of Ultra-Reliable Low-Latency Traffic via Conformal Prediction.” To appear in Signal Processing Letters, [online] arXiv preprint arXiv:2302.07675 (2023).
Recent Comments