Motivation
Hyperparameter optimization (HPO) is essential in tuning artificial intelligence (AI) models for practical engineering applications, as it governs model performance across varied deployment scenarios. Conventional HPO techniques such as random search and Bayesian optimization often focus on optimizing average performance without providing statistical guarantees, which can be limiting in high-stakes engineering tasks where system reliability is crucial. The learn-then-test (LTT) method [1], introduced in recent research, offers statistical guarantees on the average risk associated with selected hyperparameters. However, in fields like wireless networks and real-time systems, designers frequently need assurance that a specified quantile of performance will meet reliability thresholds.
To address this need, our proposed method, Quantile Learn-Then-Test (QLTT), extends LTT to offer statistical guarantees on quantiles of risk rather than just the average. This quantile-based approach provides greater robustness in real-world applications where it’s critical to control risk-aware objectives, ensuring that the system meets performance goals in a specified fraction of scenarios.
Quantile Learn-Then-Test (QLTT)
LTT, as introduced in [1], guarantees that the average risk remains within a defined threshold with high probability. However, many real-world applications require tighter control over performance measures. For instance, in cellular network scheduling, system designers may need to ensure that key performance indicators (KPIs) like latency and throughput stay within acceptable limits for a majority of users, not just on average.
Our approach, QLTT, extends LTT to provide guarantees on any specified quantile of risk. Specifically, QLTT selects hyperparameters that ensure a predefined quantile of the risk distribution meets a target threshold. This probabilistic guarantee, based on quantile risk control, better aligns with the needs of applications where performance variability is critical.
Methodology
QLTT builds on LTT’s multiple hypothesis testing framework, incorporating a quantile-specific confidence interval, obtained using [2], to achieve guarantees on the desired quantile of risk. The method takes a set of hyperparameter candidates and identifies those that meet the desired quantile threshold with high probability, enhancing reliability beyond what is possible through average risk control alone. This quantile-based approach enables QLTT to adapt to varying risk tolerance levels, making it versatile for different engineering contexts.
Experiments
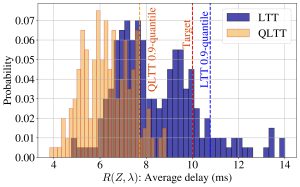
To demonstrate QLTT’s effectiveness, we applied it to a radio access scheduling problem in wireless communication [3]. Here, the task was to allocate limited resources among users with different quality of service (QoS) requirements, ensuring that latency requirements were met for the vast majority of users in real-time.
Our experimental results highlight QLTT’s advantage over LTT with respect to quantile control. While both methods controlled the average risk effectively, only QLTT managed to limit the higher quantiles of the risk distribution, reducing instances where latency exceeded critical thresholds.
The following figure compares the distributions of packet delays for conventional LTT and QLTT for a test run of the simulation. While LTT shows considerable variance, with some instances exceeding the desired threshold, QLTT consistently meets the reliability requirements by providing tighter control over risk quantiles.
Conclusion
QLTT extends the applicability of LTT by providing hyperparameter sets with guarantees on quantiles of a risk measure, thus offering a more rigorous approach to HPO for risk-sensitive engineering applications. Our experiments confirm that QLTT effectively addresses scenarios where quantile risk control is required, providing a robust solution to ensure high-confidence performance across diverse conditions.
Future work may explore expanding QLTT to more complex settings, such as other types of risk functionals and broader engineering challenges. By advancing risk-aware HPO, QLTT represents a significant step toward reliable, application-oriented AI optimization in critical industries.
References
[1] Angelopoulos, A.N., Bates, S., Candès, E.J., Jordan, M.I., & Lei, L. (2021). Learn then test: Calibrating predictive algorithms to achieve risk control. arXiv preprint arXiv:2110.01052.
[2] Howard, S.R., & Ramdas, A. (2022). Sequential estimation of quantiles with applications to A/B testing and best-arm identification. Bernoulli, 28(3), 1704–1728.
[3] De Sant Ana, P.M., & Marchenko, N. (2020). Radio Access Scheduling using CMA-ES for Optimized QoS in Wireless Networks. IEEE Globecom Workshops (GC Wkshps), pp. 1-6.
Recent Comments