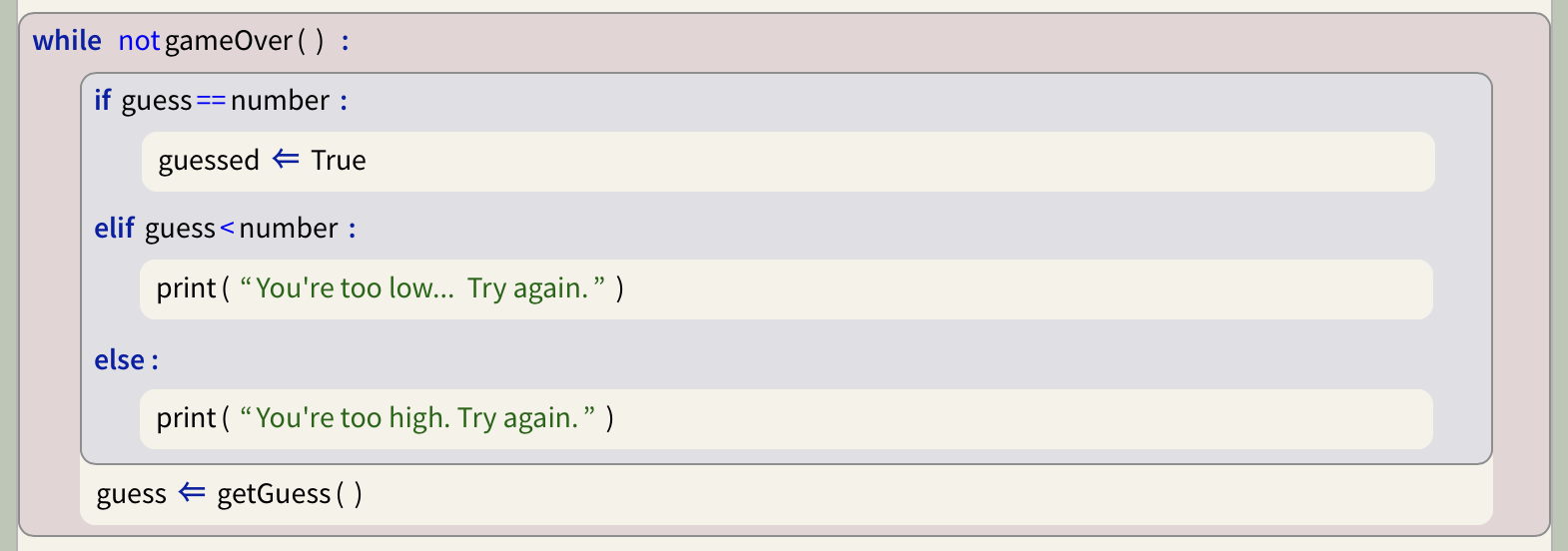
I was at a Dagstuhl seminar recently, about programming education, and one of the things we discussed were common misconceptions of novice programmers. One of these, reported by several seasoned programming teachers, was the difficulty in interpreting the assignment symbol in C-style languages:
number = 42
There are several things that can be misinterpreted here. Firstly, the equality operator is non-directional. Some students have problems remembering which way it operates. Consider this statement:
a = b
Which way does it assign? To all of us who have programmed for some time this may seem a silly question – we get used to the right-to-left semantics so thoroughly that we can hardly imagine it to be different. But for beginners? Not so clear. (And, of course, the direction is arbitrary; language designers could just as well have decided the other way.)
The second possible misconception is related to the previously learned meaning of the equals symbol: to express equality. This has been used in maths for centuries, and taught to most pupils before they ever encounter programming, and is quite different from assignment. Consider this code fragment:
a = 0;
b = a;
a = 7;
What, now, is the value of b? For learners holding the equality misconception, it will be 7. This is not entirely unreasonable; it is indeed an internally consistent mental model. The misconception is that variables, once expressed as equal, remain linked. So the equals symbol is interpreted as equality (“b is the same as a“), which might then remain true for the future.
Many people have commented for a long time that the C-style equality-as-assignment is not ideal. Many languages do better. Algol and Pascal, for example, already used a different symbol in the 1960s, quite explicitly to express the directionality more clearly, and to distinguish from equality:
number := 42
I have always like this much better than the single equals and have always been mildly annoyed by the C-style syntax.
So when we designed our language Stride recently, the question surfaced again. What should we choose?
We had two competing goals: On the one hand, we wanted the syntax to be clear and expressive, but on the other hand we want Stride to be a pathway into Java, so there is also a strong incentive to be consistent with Java syntax. (Java, of course, uses the C-style syntax, so these two goals are in conflict.)
At first, we prioritised the Java-compatibility argument and chose the equality symbol. The first release of Stride had this as the assignment operator. But then the Dagstuhl discussion happened, and I started to think again.
In Stride we have an advantage: Because the representation of the program is not directly typed in, but produced by the system in reaction to command keys, we are not restricted to characters that can easily be typed on a standard keyboard. So initially I considered going back to a syntax that Smalltalk used (in early versions, before it fell back onto the := variant), a left arrow:
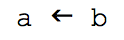
I liked it for its clarity of expression, but it has one disadvantage in a teaching language that is intended to lead to Java and similar languages: it does not directly prepare learners for the equal symbol so widely used for assignment in other languages. After we discussed this in one of our team meetings, Neil Brown, one of our team members, came up with what I think is a brilliant compromise:

This is what assignment now looks like in Stride. The double arrow still has a visual link to an equals sign, but is clearly distinct from it; it is also clearly directional. We still use the equals key as a command key to enter an assignment, further reinforcing the link for the future.
Here’s what our assignment looks like in context:
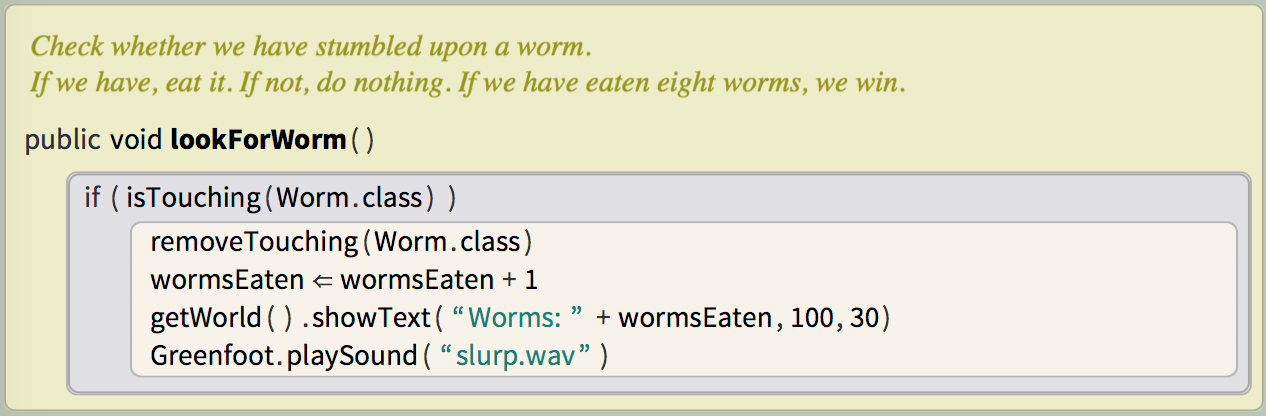
I am very happy with it. I think it reads well and is the closest we can get to reaching two competing goals.